2019Java面试宝典 -- 数据库常见面试题
作者:快盘下载 人气:1、union和union all的区别?
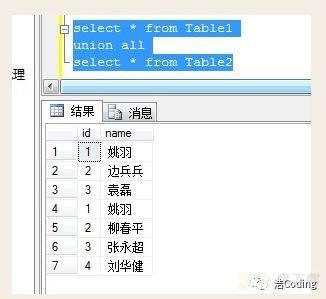
如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。两个要联合的SQL语句 字段个数必须一样,而且字段类型要“相容”(一致);union和union all的区别是,union会自动去重,而union all则将所有的结果全部显示出来,不管是不是重复。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
select * from Table1 union select * from Table2 select * from Table1 union all select * from Table2

2、Oracle的连接详解(左连接和右连接的区别)?
外连接:
左连接(左外连接Left Join):以左表作为基准进行查询,左表数据会全部显示出来,右表如果和左表匹配的数据则显示相应字段的数据,如果不匹配则显示为 null。
右连接(右外连接 Right Join):以右表作为基准进行查询,右表数据会全部显示出来,左表如果和右表匹配的数据则显示相应字段的数据,如果不匹配则显示为 null。
全连接:先以左表进行左外连接,再以右表进行右外连接。
内连接( Inner Join): 显示表之间有连接匹配的所有行。
相关SQL及解释: 关于左连接和右连接总结性的一句话:左连接where只影响右表,右连接where只影响左表。 Left Join: select * from tbl1 Left Join tbl2 where tbl1.ID = tbl2.ID 左连接后的检索结果是显示tbl1的所有数据和tbl2中满足where 条件的数据。 简言之 Left Join影响到的是右边的表。 Right Join: select * from tbl1 Right Join tbl2 where tbl1.ID = tbl2.ID 检索结果是tbl2的所有数据和tbl1中满足where 条件的数据。 简言之 Right Join影响到的是左边的表。 inner join: select * FROM tbl1 INNER JOIN tbl2 ON tbl1.ID = tbl2.ID 功能和 select * from tbl1,tbl2 where tbl1.id=tbl2.id相同。

3、SQL 的 select 语句完整的执行顺序?
SQL Select 语句完整的执行顺序:
1、from 子句组装来自不同数据源的数据; 2、where 子句基于指定的条件对记录行进行筛选; 3、group by 子句将数据划分为多个分组; 4、使用聚集函数进行计算; 5、使用 having 子句筛选分组; 6、计算所有的表达式; 7、select 的字段; 8、使用 order by 对结果集进行排序。
SQL 语言不同于其他编程语言的最明显特征是处理代码的顺序。在大多数据库语言中,代码按编码顺序被处理。但在 SQL 语句中,第一个被处理的子句式 FROM,而不是第一出现的 SELECT。
SQL 查询处理的步骤序号:
(1) FROM <left_table>
(2) <join_type> JOIN <right_table>
(3) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE | ROLLUP}
(7) HAVING <having_condition>
(8) SELECT
(9) DISTINCT
(9) ORDER BY <order_by_list>
(10) <TOP_specification> <select_list> 以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
4、常用的SQL 聚合函数?
聚合函数是对一组值进行计算并返回单一的值的函数,它经常与 select 语句中的 group by 子句一同使用。
a. avg():返回的是指定组中的平均值,空值被忽略。 b. count():返回的是指定组中的项目个数。 c. max():返回指定数据中的最大值。 d. min():返回指定数据中的最小值。 e. sum():返回指定数据的和,只能用于数字列,空值忽略。 f. group by():对数据进行分组,对执行完 group by 之后的组进行聚合函数的运算,计算每一组的值。
最后用having去掉不符合条件的组(WHERE 关键字无法与聚合函数一起使用,HAVING 子句可以让我们筛选分组后的各组数据。),having子句中的每一个元素必须出现在select列表中(只针对于mysql)。
5、简单谈下SQL注入?
通过在 Web 表单中输入(恶意)SQL 语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行 SQL 语句。举例:当执行的 sql 为 :
select * from user where username = ‘admin’ or ‘a’=‘a’
此时,sql 语句恒成立,参数 admin 毫无意义。
防止 sql 注入的方式:
1. 预编译语句:如,select * from user where username = ?,sql 语句语义不会发生改变,sql 语句中变量用?表示,即使传递参数时为“admin or ‘a’= ‘a’”,也会把这整体当做一个字符串去查询。
2. Mybatis 框架中的 mapper 方式中的 # 也能很大程度的防止 sql 注入($无法防止 sql 注入)。
6、 事务的四大特征是什么?
数据库事务 transanction 正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离性(Isolation)、持久性(Durability)。
(1)原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
(2)一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
(3)隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
(4)持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
7、常见数据库的分页语句?
MySQL——相对来说最简单分页查询:
MySQL的分页查询要用到 limit关键字,方式就是 limit m,n ;
m表示第几条数据 n表示从m+1开始取多少条数据,比如:
select * from table limit m,n 其中m是指记录开始的index,从0开始,表示第一条记录
Oracle :
Oracle分页要用到的关键字是 rownum (行号),我们直接看它的用法:
1)查询表中的前n条记录:
select * from Table where rownum <= n
2)查询第 n 到第 m 条记录:
select * from (select 表名.*, rownum rn from 表名 where rownum <=m) where rn > n;
对于这种形式的查询,oracle不像mysql那么方便,它必须使用子查询或者是集合操作来实现。
SQL Server:
在分页查询上,我感觉SQL Server比较费劲,没有一个专门的分页的语句,并且每个版本对应的查询方式不一样,下面例子是每页10条,取第31-40条数据:
--方法一:Order by Select Top (40-31+1) * From a Where ID in (Select Top 40 ID From a Order by ID ) Order by ID Desc --方法二:not in/top select top 10 * from a where id not in (select top 30 id from a order by id) order by id --方法三:not exists select top 10 * from a where not exists (select 1 from (select top 30 id from a order by id)a1 where a1.id=a.id) order by id --方法四:max/top select top 10 * from a where id>(select max(id) from (select top 30 id from a order by id)a1) order by id --方法五:row_number() select top 10 * from (select row_number()over(order by id)rownumber,* from a)a1 where rownumber>30 select * from (select row_number()over(order by id)rownumber,* from a) a1 where rownumber>30 and rownumber<41 select * from (select row_number()over(order by id)rownumber,* from a)a1 where rownumber between 31 and 40 --方法六:row_number() 变体,不基于已有字段产生记录序号,先按条件筛选以及排好序,再在结果集上给一常量列用于产生记录序号 select * from (select row_number()over(order by id)rownumber,* from (select top 40 * from a where 1=1 order by id)a )b where rownumber>30
本系列Java面试题很多代码来自网络,后加上作者的修改。如有侵权,联系作者(公众号后台留言即可)马上删除。
参考文章:
2019Java面试宝典数据库篇 -- MySQL
MySQL数据库远程连接、创建新用户、设置权限、更改用户密码
Oracle的连接详解(左连接、右连接、全连接...)?
https://www.cnblogs.com/guogl/articles/5929852.html
数据库中的左连接(left join)和右连接(right join)区别
https://www.cnblogs.com/boundless-sky/p/6594518.html
union和union all的区别?
https://www.cnblogs.com/xiangshu/articles/2054447.html
【知了堂学习笔记】JSP页面数据分页实现(一)——分页概念以及主流数据库的分页查询?
https://www.cnblogs.com/paopaolong/p/7471815.html
Java面试宝典 -- 黑马程序员
加载全部内容