百亿级MongoDB分片集群架构改造
作者:快盘下载 人气:33微信公众号:DBA随笔 关注可了解更多数据库层面的内容。问题或建议,请公众号留言;
内容目录
一、问题背景二、集群架构介绍三、MongoDB集群分片键修改方案介绍1、原生MongoDB如何修改分片键?2、数据同步方案解决分片键问题3、MongoDB数据同步工具选型4、业务流量切换四、集群架构改造后的收益五、遇到的问题及解决办法(Q&A)六、总结&优化
一、问题背景
这篇文章,是之前为核心业务做的一个MongoDB分片集群架构改造,内容很多,这里脱敏处理后,分享出来,给大家提供一个思路,更多细节,有兴趣欢迎留言。
线上业务使用MongoDB分片集群的过程中,随着数据量的增长,近期频繁发生集群性能抖动现象。排查每个分片上的日志,发现有大量慢查询,经过与开发人员的沟通过后,问题原因最终定位:
1、由于开发同学前期对于MongoDB的理解不够,导致业务查询模型(uuid)和分片集群中的分片键(_id)不匹配,大量的业务查询都会广播到每一个底层分片上。前期由于数据量少,查询慢的问题没有明显的暴漏出来,近期数据量增多,MongoDB的性能抖动问题日趋严重。
2、业务写入压力高峰时期,moveChunk频繁发生,加剧性能抖动
此外,MongoDB4.0.4版本比较老旧,部分命令性能较低且存在隐患(例如db.collection.drop()命令有可能锁库),业务期望将MongoDB线上集群从4.0.4版本升级到高版本,以解决这些问题。
对上述的问题做个总结:
1、MongoDB分片集群需要修改部分集合的分片键
2、需要升级MongoDB分片集群的版本
解决方案如下:
要想解决分片键的问题问题,可以通过两种办法: 1、DBA将MongoDB集群的分片键修改成匹配业务查询模型的分片键 2、业务侧主动修改查询模型,需要修改应用APP的代码并发布变更要想解决MongoDB数据库的版本问题,则必须从DBA侧推动。业务侧由于历史原因,修改业务逻辑难度较大。经过讨论,最终决定由DBA侧来主导修改MongoDB分片集群的分片键,同时升级MongoDB版本,改造时间周期上暂时不做过多限制。
二、集群架构介绍
本套MongoDB集群的架构图如下:

其中: 业务应用APP直接连接MongoS节点,MongoS节点共有15个; MongoS访问MongoC,MongoC是一个5副本的复制集; MongoS底层包含10个shard,每个shard都是7副本的复制集;
累计15+5+10*7=90个节点
当前MongoDB的版本是4.0.4 分片集群中包含业务数据库1个,集合35个,总计数据100多亿
三、MongoDB集群架构改造方案
1、原生MongoDB如何修改分片键?
MongoDB官方4.4版本以下,不支持shard key的修改,也就是说,shard key一旦创建,后续如果想要修改这个集合的shard key,必须删除集合,重新创建shard key;我们的线上集群版本是4.0.4,自然是不支持的。
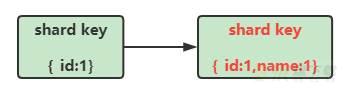
MongoDB官方4.4版本开始支持shard key的修改,但是仅仅支持shard key上的字段新增。例如,原来的shard key是{_id:1},此时支持shard key变更成为{_id:1,name:1},也就是添加一个name字段。
修改分片键使用的函数是 refineCollectionShardKey(),命令如下
db.adminCommand( { refineCollectionShardKey: "<database>.<collection>", key: { <existing key specification>, <suffix1>: <1|"hashed">, ... } } )
更详细的信息,这里给出参考文档 ,不做赘述。 参考文档:https://docs.mongodb.com/v4.4/reference/command/refineCollectionShardKey/#mongodb-dbcommand-dbcmd.refineCollectionShardKey
从上面的描述中,不难发现,MongoDB对于分片键的修改几乎是不支持直接修改的。 但是这个也很容易理解,如果支持修改分片键,每次修改完分片键之后,所有的已经落到分片上的数据,需要重新按照新的分片键来分片,可能面临着数据重组的危险,这对目前集群的写入和查询性能肯定是毁灭式的影响。所以,这个实际情况,也在意料之中。
2、数据同步方案解决分片键问题
既然MongoDB不支持直接修改,那我们换种思路,利用镜像集群的方案来进行分片键修改并升级MongoDB版本。这也是一种常用的方案,被广泛应用在数据库版本升级等场景中,简易的方案如下:
搭建一个高版本的镜像集群,分片数量、单个分片副本集数量和线上集群保持一致,分片键为修改后的正确分片键利用第三方MongoDB数据同步工具实时同步原集群的写入操作(存量数据需要提前同步)待同步完成后,应用程序切换到镜像集群,读写都切换到新的镜像集群上进行
当然,在实际操作过程中,对于上面的简易流程,会做一些补充。
可以看到,上面这个方案的关键,就是找到一个能够保证数据完整同步的MongoDB数据同步工具,而且这个同步工具必须拥有2个基本能力: 1、要能够支持分片键不同的MongoDB集群之间进行数据同步; 2、要能够支持不同版本的MongoDB 集群之间进行数据同步。
3、MongoDB数据同步工具选型
MongoDB领域,目前比较流行的数据同步方案:一种是钛铂数据的Tapdata工具,另外一种是阿里云的开源MongoShake同步工具,本次数据同步采用的是阿里云的开源数据同步工具MongoShake。具体的github地址如下:https://github.com/alibaba/MongoShake
MongoShake是一个以golang语言进行编写的通用的平台型服务,通过读取MongoDB集群的Oplog操作日志,对MongoDB的数据进行复制,后续通过操作日志实现特定需求,例如MongoDB集群间数据的异步复制,免去业务双写开销、日志订阅、离线分析、基于日志的集群监控等等。
MongoShake工具支持下面几种模式的同步:
从MongoDB副本集同步到MongoDB副本集从MongoDB副本集同步到MongoDB集群版从MongoDB集群版同步到MongoDB集群版从MongoDB副本集同步到kafka通道云上MongoDB副本集的双向同步 这里符合我们的是第3种模式,集群对集群之间的传输。
在使用MongoShake之前,我们对MongoShake的同步功能做了简单测试,总结出了以下几点使用经验: 1、MongoShake的数据同步功能分为全量同步+增量同步 2个阶段 2、全量同步阶段没有断点续传,一旦同步中断,需要重新开始;增量阶段支持断点续传,会实时记录同步偏移量信息。 3、MongoShake全量同步阶段会读取源集群数据集合的分片键、业务数据,并插入到目标集群中去,此过程中会检测分片键的一致性;
增量同步阶段只会应用Oplog中的变更内容,此过程不检测分片键的一致性,允许分片键不同的2个集群之间进行数据同步。
至此,我们根据这些特点,可以将修改分片键的整个过程进行完善:
1、搭建一个4.2.14版本的镜像集群,分片数量、单个分片副本集数量、分片键和线上集群保持一致;(图中白色代表没有数据)

2、利用开源MongoDB数据同步工具同步所有存量数据(此时源端和目标端的分片键依旧一致,都是_id,图中绿色代表存量数据);

PS:由于全量同步过程中需要消耗一定的时间,百亿数据量,大概需要3天时间,所以又会产生3天的增量数据。这些数据需要在增量阶段同步。
3、全量同步完成之后,MongoShake开启增量同步,直到增量同步追平,此时源端和目标端进入实时同步状态。

4、停止增量复制,此时目标端没有任何数据写入。将目标集群上所有需要修改分片键的集合利用mongodump导出备份,然后在目标集群上删除这些集合。

5、目标集群创建同名的新集合,并重新配置正确的分片键,将上一步备份的数据文件Data重新导入到目标端集群,至此,分片键修改完毕。

PS:上述的增量数据1是因为修改分片键过程中需要备份+恢复的操作,这个需要耗费一定时间,此时源端又会产生增量数据1.
6、重新开启增量同步,由于同增量同步支持断点续传,再次开启增量同步的时候,不需要重新全量数据,MongoShake将会从之前的中断位置进行断点续传,再次开启增量同步,基于Oplog的同步支持分片键不同的集群之间的数据同步.

7、等到源端集群和目标端集群的同步进度追平之后,由业务主导,将业务的读写流量切换到新集群即可。
4、业务流量切换
业务流量切换的过程中,需要先将读流量切换到目标集群上,确认无误后,然后再切换写流量,并且配备一套完整的回滚方案。

四、集群架构改造后的收益
本次架构改造对业务和DBA侧带来的可见收益有: 1、解决了低版本MongoDB的隐藏bug问题 2、新的分片键匹配业务查询模型,避免了查询在MongoDB集群中的广播现象, MongoDB新集群响应时间有了很大改善,p99响应时间较之前40ms降低到现在10ms左右,响应速度加快4倍。 3、新的分片键促使业务数据分布更加均匀,MongoDB moveChunk频率降低,对业务的影响大幅度减小,业务慢查询数量大幅降低,单日业务请求超时数量从1w多降低到500个,降低20倍左右。 4、DBA在整个集群迁移的过程中,通过不断试错并完善,沉淀出来一套高效、可靠、稳定的MongoDB分片集群版本升级以及分片键修改方案,为后续MongoDB此类运维工作提供了借鉴思路。 5、DBA和业务方在解决迁移过程中的问题时,对MongoDB集群架构的运维和开发规范理解程度加深,后续的运维开发工作将会更加高效。 6、其他的MongoDB高版本红利。
五、遇到的问题及解决办法(Q&A)
为保证全量数据同步过程中没有报错,我们前期在测试环境中进行了充分的测试,然而在线上实际操作过程中,还是遇到了很多问题,这里将遇到的所有问题和解决方案整理如下:
Q1、MongoShake并行同步速率过高,源集群(线上集群)读取压力过大,线上业务超时明显
A1:可以通过下面3中方法来恢复
1、降低源端数据读取并行度,表与表之间串行同步;
2、写入目标端batch_size降低,128MB到64MB;
3、写入线程并行度从8调整到4。
Q2:数据同步限速之后,全量数据同步过程时间太长,一次同步代价太大,需要优化 A2:数据同步过程中,删除目标端的索引,避免数据同步过程中,MongoDB维护目标端索引带来的CPU资源开销,加速数据同步速率
Q3:目标集群(升级改造的新集群)负载过高,数据同步速率慢(也即写入目标端性能差) A3:借用服务器,分散目标集群部署,减少单台服务器上的MongoDB实例个数,避免服务器压力过大
Q4:目标集群通过stepdown方法进行primary切换会导致数据同步中断 A4:DBA不主动通过stepdown方法触发primary切换,并调整primary节点的权重,即使同步过程中,集群自动发起选举,primary的角色也不会改变
Q5:目标集群出现主键冲突导致全量数据同步中断 A5:经排查是业务数据重复导致,业务侧修复分布式id发号器的bug,清理所有集合上主键冲突的数据纪录;DBA侧调整数据同步过程中主键冲突后的处理策略,发生冲突后,记录冲突id值,并继续同步,避免同步中断,后续进行数据补录。
Q6:增量同步期间依赖MongoDB的Oplog,Oplog中出现moveChunk相关信息,导致同步中断(基于Oplog的同步方式下,MongoShake不支持moveChunk的Oplog) A6:经过与业务方协商一致,数据同步过程中关闭源端的分片集群的平衡器(Balancer),避免源端分片集群Oplog出现moveChunk相关内容
Q7:全量同步完成瞬间,写入增量同步的偏移量失败 A7:经过反复测试,确认该问题为目标端MongoDB负载高导致写入超时,属于偶发现象。重新同步数据的同时,DBA主动联系阿里云开源工具的作者,研究偏移量计算原理,并根据同步日志输出,反解析偏移量,准备了手工写入偏移量的预案,以防止该问题重复出现。
Q8:数据校验阶段发现新集群和老集群部分集合数据不一致 A8:经过DBA和业务方逐条对比,详细排查,发现原因系源集群中存在孤儿文档,导致传统的数据统计方案存在一定统计偏差,使用新的数据统计方案后,确认真实数据纪录是一致的。
六、总结&优化
本次架构改造虽然圆满完成,但是可以总结的地方还是很多的: 1、分片键不合理的问题其实是前期集群架构设计层面的历史包袱,由于设计不合理,前期没有及时做必要的调整,导致后续花费大量的精力来重构,后续在选择集合的分片键的时候需要慎重,要综合考虑按照业务数据特点和查询模型。 2、事后分析,其实可以使用空间换时间的方案,对上述架构做一层优化。 使用级联的数据同步方法,创建2个目标集群,启动2个MongoShake数据同步进程,通过MongoDB集群级联同步的方法,源集群和中间集群之间使用全量+增量的同步模式,中间过渡集群和最终的目标集群之间采用增量同步的模式,这样,可以减少数据的导出备份、重新恢复这个过程,可以减少总体的时间。
更多细节,后续会追加补充。
加载全部内容