Visual-Attention-Network
作者:快盘下载 人气:论文阅读
Visual Attention Network Arxiv
有两种常见的方式去捕捉长距离的依赖(long-range dependence);
a)使用自注意力机制。自注意力擅长处理一维的序列结构;如果直接用于处理图像;会忽略图像自身的二维结构信息。由于自注意力自身的复杂度问题;难以用于处理高分辨率图像。自注意力机制仅仅考虑了空间上了自适应性;而忽略了通道维度上的自适应性.
b)使用大核卷积来捕捉长距离依赖。大核卷积的不足在于;大卷积核的参数量和计算量太大;难以接受。
文献提出了一种全新的针对于视觉任务的注意力机制;大核注意力机制;Large-Kernel Attention;LKA;,并基于LAK提出一种新的简单且有效的视觉主干网络 Visual Attention Network (VAN)。
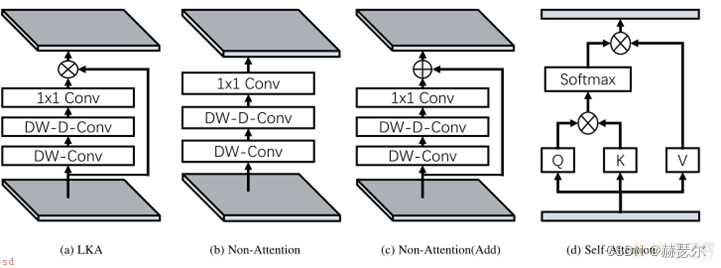
(1)大核卷积的分解;与MobileNet有相似之处;MobileNet将标准卷积分为为两部分;一个深度卷积和一个点卷积(1 × 1 Conv)。而LKA将卷积分解为三部分;深度卷积、深度扩张卷积、和点卷积。

LKA将一个K×K卷积分解为一个k/d×k/d的深度卷积、一个(2d−1)×(2d−1)深度膨胀卷积;扩张率为d;和一个1×1卷积。通过上述分解;可以捕捉到计算成本和参数很小的远程关系。在获得远程关系后;可以生成注意力图。
class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
(2)LKA:基于大核卷积的注意力

class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x ; shorcut
return x
(3)Block:VAN的一个Block
VAN整体采用Swin Transformer的分层结构;文献作者在图像的分类检测分割上作对比实验;实验效果显示VAN在性能上超过 Swin Transformer 和 ConvNeXt。

class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = Attention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x ; self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
x = x ; self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
VAN整体采用Swin Transformer的分层结构;文献作者在图像的分类检测分割上作对比实验;实验效果显示VAN在性能上超过 Swin Transformer 和 ConvNeXt。
加载全部内容