阿里云构建千万级别架构演变之路
作者:快盘下载 人气:一个好的架构是靠演变而来;而不是单纯的靠设计。刚开始做架构设计;我们不可能考虑到架构的高性能;高扩展;高安全等各方面的因素。随着业务需求越来越多;业务的访问压力也越来越大;架构也在不断的演变及进化。
一; 架构的原始阶段
万能的单机
架构的最原始阶段;即一台ECS;Elastic Compute Service弹性计算服务;服务器搞定一切。对应的web服务;db;静态文件资源都部署到同一台ECS上就ok。
一般5万-30w的pv访问量;结合系统内核参数调优;web应用的性能参数调优;数据库调优;基本上能为稳定的运行

二;架构基础阶段
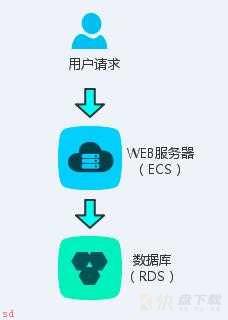
web应用;数据库应用 物理分离
当访问量达到50万-100万pv的时候;部署在一台服务器上的web应用和数据库应用;会对服务器的cpu;内存;磁盘IO;带宽等系统资源进行竞争。;产生资源竞争;。这时候就出现了瓶颈。
解决方案;
将web应用和数据库应用进行物理隔离;单独部署。来解决性能问题
采用ECS;RDS模式
三; 架构动静分离阶段
静态缓存;文件存储
通过将动态请求和静态请求的访问分离;有效解决服务器的cpu;内存 磁盘IO;以及带宽压力
当访问量到100万-300万pv的时候;这时候前端web服务出现性能瓶颈。大量的web请求阻塞;同时服务器的cpu;内存;磁盘IO;带宽都有压力。
解决方案;
1 将网站的静态资源 存储在oss上;静态资源包括;网站图片;html;js;css文件;
2 通过cdn将静态资源分布式缓存在各个节点上实现“”就近访问“”
架构采用;CDN;ECS;OSS;RDS

四; 架构分布式阶段 负载均衡
当访问量达到300万-500万pv的时候;虽然“”动静分离“”有效分离了静态请求的压力;但是动态请求的压力已经让服务器吃不消了。最直观的现象是;
瓶颈;
1 前端访问阻塞;延迟;服务器进程增多;cpu100%
2 出现常见的502,503 504 的错误码
单台web服务器已经无法满足需求;需要通过负载均衡技术增加多台web服务器;对应ECS可以选择不同可用区;进步一保障高可用; 告别单机时代;转变为分布式架构阶段
解决方案;
架构采用;CDN;SLB;;ECS1;ECS2;;;;;OSS;RDS

五; 架构数据缓存阶段
数据库缓存
当访问量到500万-1000万pv的时候
虽然负载均衡;多台ECS解决了动态请求的性能压力;但是这时候我们发现;数据库出现了
瓶颈:
1 RDS的连接数增加 并且阻塞;
2 cpu100% IO PS 飙升
解决方案;
通过数据库缓存;有效减少数据库访问压力;进一步提升性能
架构采用;
CDN;SLB;;ECS1;;;;;OSS;云数据库memchace;或者redis;;RDS

六; 架构扩展阶段
垂直扩展
当访问量到1000万-5000万pv。虽然这个时候我们可以看到通过分布式文件系统OSS已经解决了文件存储的性能问题
cdn也解决了静态资源访问的性能问题。但是当访问量再次增加;这个时候web服务器和数据库方面依然是瓶颈。
解决方案;
在此;我们通过垂直扩展;进一步切分web服务器和数据库的压力;解决性能问题
“”垂直扩展“”;按照不同的业务;或者数据库;;切分到不同的服务器;数据库;上;这种切分叫垂直扩展
垂直扩展第一招; 业务拆分
在业务层;可以把不同的功能模块拆分到不同的服务器上进行单独部署。比如;用户模块;订单模块;商品模块等;拆分到不同的服务器上部署
垂直扩展第二招;数据库读写分离
在数据库层;当结合结合数据库缓存;数据库压力还是很大的时候;我们可以通过读写分离的方式;进一步切分及降低数据库的压力
垂直扩展第三招;分库;分表
我们可以把用户模块;订单模块;商品模块分别存放到不同的数据库中;如用户模块库;订单模块库;商品模块库
架构采用;
CDN;SLB;;ECS;;);OSS;云数据库memcache;redis;;RDS读写分离

七;架构分布式;大数据阶段;水平扩展
当访问量达到5000万pv以及以上的时候;垂直扩展的框架也已经开始“”山穷水尽了“”
瓶颈;
1 读写分离仅解决 读 的压力; 面对高访问量的时候;数据库在“”写“”的压力上面“”力不从心了“”;
2 分库虽然将压力拆分到不同的数据库中。但单表达到TB级别以上;显然已经达到传统关系型数据库处理的极限
水平扩展第一招; 增加更多的web服务器
通过业务垂直拆分部署在不同的服务器后;当后续压力进一步增大;增加更多的webservice 进行水平扩展
水平扩展第二招;增加更多的SLB
单台SLB也存在单点故障的风险;即slb也存在性能极限;如qps最大值5w;通过DNS轮询;将请求轮询转发至不同可用区的SLB上面;实现SLB水平扩展
水平扩展第三招;采用分布式缓存
单台存在性能极限 ;最大吞吐峰值为512Mbps
我们可以部署多台memcache;在代码层通过hash算法将数据分别缓存至不同的云数据库中
水平扩展第四招; sharding;nosql
面对高并发;大数据的需求;传统的关系型数据库已不在适用。
采用; DRDS;mysql sharding 分布式解决方案;;OTS;基于列存储的分布式数据库; 对应的分布式数据库来根本性的解决问题。
架构采用CDN;DNS轮询;SLB;ECS;OSS;云数据库memcache;DROS;OTS;现在已更名为表格存储Table Store;

加载全部内容