利用机器学习构建我国历史PM2.5浓度数据集
作者:快盘下载 人气:
自2013年以来我国建立了覆盖全国的空气质量观测站点来实时监测近地面PM2.5浓度。但是这些观测数据受限于较短的时间覆盖以及不均匀的空间分布,很难用来描述我国长期PM2.5变化特征。目前国内外很多研究已经利用卫星反演的气溶胶光学厚度(AOD)产品来近似估算中国近地面PM2.5浓度。而卫星数据在很大程度上受反演算法的影响,且受限于时间覆盖,很难用于研究长期PM2.5浓度变化趋势及其对环境和气候变化的影响。
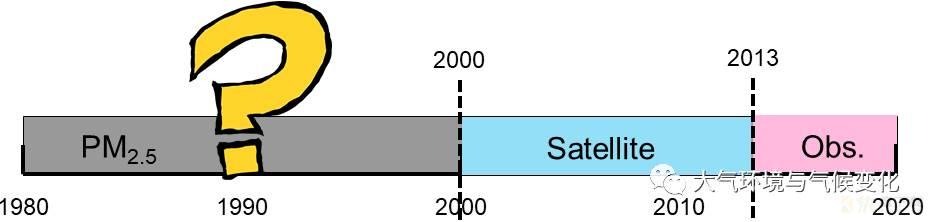
为解决这一问题,本研究选择影响PM2.5浓度的主要因素,包括大气能见度观测数据以及其他辅助数据(包括多种气象参数、人为排放、土地利用、地形、人口和站点时空信息),结合时空随机森林方法,构建了中国1980–2019年近地面PM2.5浓度数据集。与基于卫星产品AOD反演的PM2.5浓度相比,该数据集具有更长的时间覆盖范围,并且更能代表近地面气溶胶,为研究气溶胶变化对环境和气候的影响提供了有效工具。数据现已公开下载使用。

图1.技术路线
用2014–2018年的PM2.5观测数据作为训练集的目标值,辅助变量作为特征来训练模型,利用2019年的PM2.5来估算模型的预测能力。采用十折交叉验证法验证模型的精度,结果表明模型的表现出色,该模型的PM2.5预测值与观测值的决定系数(R2)和均方根误差(RMSE)分别为0.96和7.12 μg/m3。

图2.(a)模型拟合能力;(b)模型预测能力的密度散点图
利用双线性插值法将模型估算的PM2.5插值成1°格点数据,估算数据能够很好地再现我国PM2.5空间分布和季节变化,格点数据与观测值整体之间的R2>0.8,标准平均偏差(NMB)<13%。根据模型估算得到的数据,可以看出我国年均PM2.5在1980–2014年逐步上升,2014年后显著下降;1980–2014年中国东部PM2.5浓度增加,最大增速为5–10 μg/m3/decade;实行污染减排后,2014–2019年华北平原PM2.5的降低速率超过50 μg/m3/decade,证实了污染减排政策的有效性。

图3. 观测、预测和网格插值后的冬季PM2.5空间分布

图4. (a)1980–2014年、(b) 2014–2019年PM2.5浓度的线性趋势
论文信息
上述成果以“Constructing a spatiotemporally coherent long-term PM2.5concentration dataset over China during 1980–2019 using a machine learning approach”为题发表于《Science of the Total Environment》(SCI一区Top期刊,影响因子7.963)。南京信息工程大学环境科学与工程学院2019级硕士生李慧敏为论文第一作者,南京信息工程大学杨洋教授为论文通讯作者,参与作者包括南京信息工程大学环科院廖宏教授以及美国西北太平洋国家实验室王海龙研究院等。本研究得到了国家自然科学基金(4197159)和国家重点研发计划(2019YFA0606800、2020YFA0607803)的支持。
Li, H., Yang, Y., Wang, H., Li, B., Wang, P., Li, J., Liao, H. Constructing a spatiotemporally coherent long-term PM2.5 concentration dataset over China using a machine learning approach. Sci. Total Environ. 765, 144263, https://doi.org/10.1016/j.scitotenv.2020.144263, 2021.
加载全部内容