深入理解Linux电源管理
作者:快盘下载 人气:作者简介:
程磊,某手机大厂系统开发工程师,阅码场荣誉总编辑,最大的爱好是钻研Linux内核基本原理。
目录:
一、电源管理框架
1.1 电源状态管理
1.2 省电管理
1.3 电源管理质量
二、睡眠与休眠
2.1 冻结进程
2.2 睡眠流程
2.3 休眠流程
2.4 自动睡眠
三、关机与重启
3.1 用户空间处理
3.2 内核处理
四、CPU动态调频
4.1 CPUFreq Core
4.2 Govener介绍
4.3 Driver介绍
五、CPU休闲
5.1 CPUIdle Core
5.2 决策者介绍
5.3 Driver介绍
六、电源管理质量
6.1 系统级约束
6.2 设备级约束
七、总结回顾
一、电源管理框架
计算机运行在物理世界中,物理世界中的一切活动都需要消耗能量。能量的形式有很多种,如热能、核能、化学能等。计算机消耗的是电能,其来源是电池或者外电源。计算机内部有一个部件叫做电源管理芯片(PMIC),它接收外部的电能,然后转化为不同电压的电流,向系统的各个硬件供电。什么硬件需要多少伏的电压,都是由相应的电气标准规定好了的,各个硬件厂商按照标准生成硬件就可以了。上电的过程是由硬件自动完成的,不需要软件的参与。因为硬件不上电的话,软件也没法运行啊。但是当硬件运行起来之后,软件就可以对硬件的电源状态进行管理了。电源管理的内容包括电源状态管理和省电管理。电源状态管理是对整个系统的供电状态进行管理,内容包括睡眠、休眠、关机、重启等操作。省电管理是因为电能不是免费的,我们应该尽量地节省能源,尤其是对于一些手持设备来说,电能虽然并不昂贵但是却非常珍贵,因为电池的容量非常有限。不过省电管理也不能一味地省电,还要考虑性能问题,在性能与功耗之间达到平衡。
1.1 电源状态管理
计算机只有开机之后才能使用,但是我们并不是一直都在使用计算机。当我们短时间不使用计算机时,可以把它置入睡眠或者休眠状态,这样可以省电,而且当我们想使用时还可以快速地恢复到可用状态。当我们长时间不使用计算机时,就可以把它关机,这样更省电,当然再使用它时还需要重新开机。有时候我们觉得系统太卡或者系统状态不对的时候,还可以对计算机进行重启,让系统重新恢复到一个干净稳定的状态。
睡眠(Sleep)也叫做Suspend to RAM(STR),挂起到内存。休眠(Hibernate)也叫做Suspend to Disk(STD)。有时候我们会把睡眠叫做挂起(Suspend),但是有时候我们也会把睡眠和休眠统称为挂起(Suspend)。系统睡眠的时候会把系统的状态信息保存到内存,然后内存要保持供电,其它设备都可以断电。系统休眠的时候会把系统的状态信息保存到磁盘,此时整个系统都可以断电,就和关机一样。系统无论睡眠还是休眠,都可以被唤醒。对于睡眠来说很多外设都可以唤醒整个系统,比如键盘。对于休眠来说,就只有电源按钮能唤醒系统了。休眠一方面和睡眠比较像,都保存了系统的状态信息,一方面又和关机比较像,整个系统都断电了。
重启和关机的关系比较密切,重启相当于是关机再开机。二者都是用reboot系统调用来实现的,其参数cmd用来指定是关机还是重启。关机和重启是需要init进程来处理的,无论我们是使用命令还是使用系统的关机按钮还是直接按电源键,事件最终都会被传递给init进程。Init接收到关机或重启命令后,会进行一些保存处理,然后停止所有的服务进程、杀死所有的普通进程,最后调用系统调用reboot进行关机或者重启。
1.2 省电管理
我们不使用电脑时可以进行睡眠、休眠甚至关机来进行省电,但是我们使用电脑时也可以有很多办法来省电。这些省电方法又可以分为两类,使用省电和闲暇省电。闲暇省电是指计算机在宏观上整体上还在使用,但是在微观上局部上有的设备暂时不在使用。使用省电的方法就是动态调频,包括CPU动态调频(CPUFreq)和设备动态调频(DevFreq)。你正在使用着还想要省电,那唯一的方法就是降低频率了。降低频率就会降低性能,所以还要考虑性能,结合当时的负载进行动态调频。闲暇省电的方法就比较多了,包括CPU休闲(CPUIdle)、CPU热插拔(CPU Hotplug)、CPU隔离(Core Isolate)和动态PM(Runtime PM)。CPUIdle指的是当某个CPU上没有进程可调度的时候可以暂时局部关掉这个CPU的电源,从而达到省电的目的,当再有进程需要执行的时候再恢复电源。CPU Hotplug指的是我们可以把某个CPU热移除,然后系统就不会再往这个CPU上派任务了,这个CPU就可以放心地完全关闭电源了,当把这个CPU再热插入之后,就对这个CPU恢复供电,这个CPU就可以正常执行任务了。CPU隔离指的是我们把某个CPU隔离开来,系统不再把它作为进程调度的目标,这样这个CPU就可以长久地进入Idle状态了,达到省电的目的。不过CPU隔离并不是专门的省电机制,我们把CPU隔离之后还可以通过set_affinity把进程专门迁移到这个CPU上,这个CPU还会继续运行。CPU隔离能达到一种介于CPUIdle和CPU热插拔之间的效果。Runtime PM指的是设备的动态电源管理,系统中存在很多设备,但是并不是每种设备都在一直使用,比如相机可能在大部分时间都不会使用,所以我们可以在大部分时间把相机的电源关闭,在需用相机的时候,再给相机供电。
1.3 电源管理质量
省电管理可以达到省电的目的,但是也会降低系统的性能,包括响应延迟、带宽、吞吐量等。所以内核又提供了一个PM QOS框架,QoS是Quality Of Service(服务质量)。PM QoS框架一面向顾客提供接口,顾客可以通过这些接口对系统的性能提出要求,一面向各种省电机制下发要求,省电机制在省电的同时也要满足这些性能要求。PM QoS的顾客包括内核和进程:对于内核,PM QoS提供了接口函数可以直接调用;对于进程,PM QoS提供了一些设备文件可以让用户空间进行读写。PM QoS对某一项性能指标的要求叫做一个约束,约束分为系统级约束和设备级约束。系统级约束针对的是整个系统的性能要求,设备级约束针对的是某个设备的性能要求。
下面我们画个图总结一下电源管理:

二、睡眠与休眠
睡眠和休眠的整体过程是相似的,都是暂停系统的运行、保存系统信息、关闭全部或大部分硬件的供电,当被唤醒时的过程正好相反,先恢复供电,然后恢复系统的运行,再恢复之前保存的信息,然后就可以正常使用了。暂停系统运行包括以下操作:同步文件数据到磁盘、冻结几乎所有进程、暂停devfreq和cpufreq、挂起所有设备(调用所有设备的suspend函数)、禁用大部分外设的中断、下线所有非当前CPU。对于睡眠来说,内存是不断电的,所以不用保存信息。对于休眠来说整个系统是要断电的,所以要把很多系统关键信息都保存到swap中。然后系统就可以断电进入睡眠或者休眠状态了。对于睡眠来说有很多外设都可以唤醒系统,对于休眠来说只有电源键能唤醒系统。当系统被唤醒时就开始了恢复操作,睡眠的恢复和休眠的恢复操作是不太一样的。睡眠基本上是上面操作的反操作,休眠是先正常启动,然后在启动的末尾从swap区恢复状态信息。
2.1 冻结进程
睡眠和休眠都有冻结进程的流程,我们就先来看一看冻结进程的过程。冻结进程是先冻结普通进程,再冻结内核进程,其中有些特殊进程不冻结,当前进程不冻结。冻结的方法是先把一个全局变量pm_freezing设置为true,然后给每个进程都发送一个伪信号,也就是把所有进程都唤醒。进程唤醒之后会运行,在其即将返回用户空间时会进行信号处理,在信号处理的流程中,会先进行冻结检测,如果发现pm_freezing为true而且当前进程也不是免冻进程,那么就会冻结该进程。冻结方法也很简单,就是把进程的运行状态设置为不可运行,然后调度其它进程。
下面我们看一下冻结的流程,代码进行了极度删减,只保留最关键的部分。
linux-src/kernel/power/process.c
int freeze_processes(void)
{
pm_freezing = true;
try_to_freeze_tasks(true);
}
static int try_to_freeze_tasks(bool user_only)
{
for_each_process_thread(g, p) {
freeze_task(p)
}
} linux-src/kernel/freezer.c
bool freeze_task(struct task_struct *p)
{
fake_signal_wake_up(p);
}
static void fake_signal_wake_up(struct task_struct *p)
{
unsigned long flags;
if (lock_task_sighand(p, &flags)) {
signal_wake_up(p, 0);
unlock_task_sighand(p, &flags);
}
} linux-src/arch/x86/kernel/signal.c
void arch_do_signal_or_restart(struct pt_regs *regs, bool has_signal)
{
struct ksignal ksig;
if (has_signal && get_signal(&ksig)) {
/* Whee! Actually deliver the signal. */
handle_signal(&ksig, regs);
return;
}
} linux-src/kernel/signal.c
bool get_signal(struct ksignal *ksig)
{
try_to_freeze();
} linux-src/include/linux/freezer.h
static inline bool try_to_freeze(void)
{
return try_to_freeze_unsafe();
}
static inline bool try_to_freeze_unsafe(void)
{
if (likely(!freezing(current)))
return false;
return __refrigerator(false);
}
static inline bool freezing(struct task_struct *p)
{
if (likely(!atomic_read(&system_freezing_cnt)))
return false;
return freezing_slow_path(p);
} linux-src/kernel/freezer.c
bool freezing_slow_path(struct task_struct *p)
{
if (p->flags & (PF_NOFREEZE | PF_SUSPEND_TASK))
return false;
if (test_tsk_thread_flag(p, TIF_MEMDIE))
return false;
if (pm_nosig_freezing || cgroup_freezing(p))
return true;
if (pm_freezing && !(p->flags & PF_KTHREAD))
return true;
return false;
}
bool __refrigerator(bool check_kthr_stop)
{
unsigned int save = get_current_state();
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
was_frozen = true;
schedule();
}
set_current_state(save);
return was_frozen;
} 冻结流程并不是一条线执行完成的,分为发送冻结信号把每个进程都唤醒,然后每个进程自己在运行的时候自己把自己冻结了。
2.2 睡眠流程
下面我们来看一下睡眠流程的代码: linux-src/kernel/power/suspend.c
int pm_suspend(suspend_state_t state)
{
int error;
if (state <= PM_SUSPEND_ON || state >= PM_SUSPEND_MAX)
return -EINVAL;
pr_info("suspend entry (%s)
", mem_sleep_labels[state]);
error = enter_state(state);
if (error) {
suspend_stats.fail++;
dpm_save_failed_errno(error);
} else {
suspend_stats.success++;
}
pr_info("suspend exit
");
return error;
}
static int enter_state(suspend_state_t state)
{
int error;
if (sync_on_suspend_enabled) {
ksys_sync_helper();
}
error = suspend_prepare(state);
error = suspend_devices_and_enter(state);
return error;
}
static int suspend_prepare(suspend_state_t state)
{
int error;
trace_suspend_resume(TPS("freeze_processes"), 0, true);
error = suspend_freeze_processes();
trace_suspend_resume(TPS("freeze_processes"), 0, false);
return error;
}
int suspend_devices_and_enter(suspend_state_t state)
{
int error;
error = platform_suspend_begin(state);
suspend_console();
suspend_test_start();
error = dpm_suspend_start(PMSG_SUSPEND);
do {
error = suspend_enter(state, &wakeup);
} while (!error && !wakeup && platform_suspend_again(state));
Resume_devices:
dpm_resume_end(PMSG_RESUME);
suspend_test_finish("resume devices");
resume_console();
Close:
platform_resume_end(state);
pm_suspend_target_state = PM_SUSPEND_ON;
return error;
} linux-src/drivers/base/power/main.c
int dpm_suspend_start(pm_message_t state)
{
ktime_t starttime = ktime_get();
int error;
error = dpm_prepare(state);
if (error) {
suspend_stats.failed_prepare++;
dpm_save_failed_step(SUSPEND_PREPARE);
} else
error = dpm_suspend(state);
dpm_show_time(starttime, state, error, "start");
return error;
}
int dpm_suspend(pm_message_t state)
{
int error = 0;
devfreq_suspend();
cpufreq_suspend();
while (!list_empty(&dpm_prepared_list)) {
struct device *dev = to_device(dpm_prepared_list.prev);
get_device(dev);
error = device_suspend(dev);
}
return error;
} linux-src/kernel/power/suspend.c
static int suspend_enter(suspend_state_t state, bool *wakeup)
{
int error;
error = platform_suspend_prepare(state);
error = dpm_suspend_late(PMSG_SUSPEND);
error = platform_suspend_prepare_late(state);
error = dpm_suspend_noirq(PMSG_SUSPEND);
error = platform_suspend_prepare_noirq(state);
error = suspend_disable_secondary_cpus();
arch_suspend_disable_irqs();
BUG_ON(!irqs_disabled());
system_state = SYSTEM_SUSPEND;
error = syscore_suspend();
if (!error) {
*wakeup = pm_wakeup_pending();
if (!(suspend_test(TEST_CORE) || *wakeup)) {
error = suspend_ops->enter(state);
} else if (*wakeup) {
error = -EBUSY;
}
syscore_resume();
}
system_state = SYSTEM_RUNNING;
arch_suspend_enable_irqs();
BUG_ON(irqs_disabled());
Enable_cpus:
suspend_enable_secondary_cpus();
Platform_wake:
platform_resume_noirq(state);
dpm_resume_noirq(PMSG_RESUME);
Platform_early_resume:
platform_resume_early(state);
Devices_early_resume:
dpm_resume_early(PMSG_RESUME);
Platform_finish:
platform_resume_finish(state);
return error;
} 2.3 休眠流程
下面我们来看一下休眠流程的代码:
linux-src/kernel/power/hibernate.c
int hibernate(void)
{
int error;
lock_system_sleep();
pm_prepare_console();
ksys_sync_helper();
error = freeze_processes();
lock_device_hotplug();
error = create_basic_memory_bitmaps();
error = hibernation_snapshot(hibernation_mode == HIBERNATION_PLATFORM);
if (in_suspend) {
pm_pr_dbg("Writing hibernation image.
");
error = swsusp_write(flags);
swsusp_free();
if (!error) {
power_down();
}
}
return error;
} linux-src/kernel/power/snapshot.c
int create_basic_memory_bitmaps(void)
{
struct memory_bitmap *bm1, *bm2;
int error = 0;
bm1 = kzalloc(sizeof(struct memory_bitmap), GFP_KERNEL);
error = memory_bm_create(bm1, GFP_KERNEL, PG_ANY);
bm2 = kzalloc(sizeof(struct memory_bitmap), GFP_KERNEL);
error = memory_bm_create(bm2, GFP_KERNEL, PG_ANY);
forbidden_pages_map = bm1;
free_pages_map = bm2;
mark_nosave_pages(forbidden_pages_map);
return 0;
} linux-src/kernel/power/hibernate.c
int hibernation_snapshot(int platform_mode)
{
int error;
error = platform_begin(platform_mode);
error = hibernate_preallocate_memory();
error = freeze_kernel_threads();
error = dpm_prepare(PMSG_FREEZE);
suspend_console();
pm_restrict_gfp_mask();
error = dpm_suspend(PMSG_FREEZE);
error = create_image(platform_mode);
msg = in_suspend ? (error ? PMSG_RECOVER : PMSG_THAW) : PMSG_RESTORE;
dpm_resume(msg);
resume_console();
dpm_complete(msg);
Close:
platform_end(platform_mode);
return error;
}
static void power_down(void)
{
switch (hibernation_mode) {
case HIBERNATION_REBOOT:
kernel_restart(NULL);
break;
case HIBERNATION_PLATFORM:
hibernation_platform_enter();
fallthrough;
case HIBERNATION_SHUTDOWN:
if (pm_power_off)
kernel_power_off();
break;
}
kernel_halt();
/*
* Valid image is on the disk, if we continue we risk serious data
* corruption after resume.
*/
pr_crit("Power down manually
");
while (1)
cpu_relax();
} 上面是休眠的过程,下面我们来看一下休眠恢复的过程,休眠恢复是先正常开机,然后从swap分区中加载之前保存的数据。
linux-src/kernel/power/hibernate.c
late_initcall_sync(software_resume);
static int software_resume(void)
{
int error;
if (swsusp_resume_device)
goto Check_image;
if (resume_delay) {
pr_info("Waiting %dsec before reading resume device ...
",
resume_delay);
ssleep(resume_delay);
}
/* Check if the device is there */
swsusp_resume_device = name_to_dev_t(resume_file);
if (!swsusp_resume_device) {
wait_for_device_probe();
if (resume_wait) {
while ((swsusp_resume_device = name_to_dev_t(resume_file)) == 0)
msleep(10);
async_synchronize_full();
}
swsusp_resume_device = name_to_dev_t(resume_file);
if (!swsusp_resume_device) {
error = -EnodeV;
goto Unlock;
}
}
Check_image:
pm_pr_dbg("Hibernation image partition %d:%d present
",
MAJOR(swsusp_resume_device), MINOR(swsusp_resume_device));
pm_pr_dbg("Looking for hibernation image.
");
error = swsusp_check();
if (error)
goto Unlock;
/* The snapshot device should not be opened while we're running */
if (!hibernate_acquire()) {
error = -EBUSY;
swsusp_close(FMODE_READ | FMODE_EXCL);
goto Unlock;
}
error = freeze_processes();
error = freeze_kernel_threads();
error = load_image_and_restore();
thaw_processes();
Finish:
pm_notifier_call_chain(PM_POST_RESTORE);
Restore:
pm_restore_console();
pr_info("resume failed (%d)
", error);
hibernate_release();
/* For success case, the suspend path will release the lock */
Unlock:
mutex_unlock(&system_transition_mutex);
pm_pr_dbg("Hibernation image not present or could not be loaded.
");
return error;
Close_Finish:
swsusp_close(FMODE_READ | FMODE_EXCL);
goto Finish;
}
static int load_image_and_restore(void)
{
int error;
lock_device_hotplug();
error = create_basic_memory_bitmaps();
error = swsusp_read(&flags);
swsusp_close(FMODE_READ | FMODE_EXCL);
error = hibernation_restore(flags & SF_PLATFORM_MODE);
swsusp_free();
free_basic_memory_bitmaps();
Unlock:
unlock_device_hotplug();
return error;
}
int hibernation_restore(int platform_mode)
{
int error;
pm_prepare_console();
suspend_console();
pm_restrict_gfp_mask();
error = dpm_suspend_start(PMSG_QUIESCE);
if (!error) {
error = resume_target_kernel(platform_mode);
/*
* The above should either succeed and jump to the new kernel,
* or return with an error. Otherwise things are just
* undefined, so let's be paranoid.
*/
BUG_ON(!error);
}
dpm_resume_end(PMSG_RECOVER);
pm_restore_gfp_mask();
resume_console();
pm_restore_console();
return error;
} 2.4 自动睡眠
随着智能手机的普及,手机的电量问题也越来越严重。之前的手机都是充一次能用三到五天甚至七天以上,但是对于智能手机来说,充一次只能用一天或者半天。手机电池技术迟迟没有大的突破,为此也只能从软件上下手解决了。安卓系统为此采取的办法是投机性睡眠,也就是说对于手机来说,睡眠是常态,运行不是常态,这也符合手机的使用习惯,一天24小时大部分时间是不用手机的。安卓在内核中添加了wakelock模块,内核默认情况下总是尝试去睡眠,除非受到了wakelock的阻止。用户空间的各个模块都可以向内核添加wakelock,以表明自己需要运行,系统不能去睡眠。当用户空间都把自己的wakelock移除之后,内核没了wakelock就会去睡眠了。Wakelock推出之后,受到了很多内核核心维护者的强烈批评,wakelock的源码也一直没有合入标准内核。后来内核又重新实现了wakelock的逻辑,叫做自动睡眠。
其代码如下: linux-src/kernel/power/autosleep.c
int __init pm_autosleep_init(void)
{
autosleep_ws = wakeup_source_register(NULL, "autosleep");
if (!autosleep_ws)
return -ENOMEM;
autosleep_wq = alloc_ordered_workqueue("autosleep", 0);
if (autosleep_wq)
return 0;
wakeup_source_unregister(autosleep_ws);
return -ENOMEM;
}
static void try_to_suspend(struct work_struct *work)
{
unsigned int initial_count, final_count;
if (!pm_get_wakeup_count(&initial_count, true))
goto out;
mutex_lock(&autosleep_lock);
if (!pm_save_wakeup_count(initial_count) ||
system_state != SYSTEM_RUNNING) {
mutex_unlock(&autosleep_lock);
goto out;
}
if (autosleep_state == PM_SUSPEND_ON) {
mutex_unlock(&autosleep_lock);
return;
}
if (autosleep_state >= PM_SUSPEND_MAX)
hibernate();
else
pm_suspend(autosleep_state);
mutex_unlock(&autosleep_lock);
if (!pm_get_wakeup_count(&final_count, false))
goto out;
/*
* If the wakeup occurred for an unknown reason, wait to prevent the
* system from trying to suspend and waking up in a tight loop.
*/
if (final_count == initial_count)
schedule_timeout_uninterruptible(HZ / 2);
out:
queue_up_suspend_work();
} 三、关机与重启
关机和重启是我们平时使用电脑时用的最多的操作了。重启也是一种关机,只不是关机之后再开机,所以把它们放在一起讲,实际上它们的代码也是在一起实现的。后文中我们用关机来同时指代关机和重启。关机的过程分为两个部分,用户空间处理和内核处理。正常的关机的话,我们肯定不能直接拔电源,也不能让内核直接去关机,因为用户空间也运行着大量的进程,也要对它们进行妥善的处理。由于init进程是所有用户空间进程的祖先,所以由init进程处理关机命令是最合适不过的。实际上无论你是用命令行关机还是图形界面按钮关机还是长按电源键关机,最终的关机命令都会发给init进程来处理。Init进程首先会stop各个服务进程,然后杀死其它用户空间进程,最后使用reboot系统调用请求内核进行最后的关机操作。
3.1 用户空间处理
我们使用命令reboot或者图形界面关机时,最终都会把命令发给init进程来处理。Init进程会首先关闭各个服务进程(deamon),然后发送信号SIGTERM给所有其他进程,给其一次优雅地退出的机会,并sleep一段时间(一般是3s)来等待其退出,接着再发送信号SIGKILL给那么还是没有退出的进程,强制其退出。最后Init进程会调用sync把内存中的文件数据同步到磁盘,最终通过reboot系统调用请求内核来关机。
3.2 内核处理
我们来看一下内核总reboot系统调用的实现:
linux-src/kernel/reboot.c
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
void __user *, arg)
{
struct pid_namespace *pid_ns = task_active_pid_ns(current);
char buffer[256];
int ret = 0;
/* We only trust the superuser with rebooting the system. */
if (!ns_capable(pid_ns->user_ns, CAP_SYS_BOOT))
return -EPERM;
/* For safety, we require "magic" arguments. */
if (magic1 != LINUX_REBOOT_MAGIC1 ||
(magic2 != LINUX_REBOOT_MAGIC2 &&
magic2 != LINUX_REBOOT_MAGIC2A &&
magic2 != LINUX_REBOOT_MAGIC2B &&
magic2 != LINUX_REBOOT_MAGIC2C))
return -EINVAL;
/*
* If pid namespaces are enabled and the current task is in a child
* pid_namespace, the command is handled by reboot_pid_ns() which will
* call do_exit().
*/
ret = reboot_pid_ns(pid_ns, cmd);
if (ret)
return ret;
/* Instead of trying to make the power_off code look like
* halt when pm_power_off is not set do it the easy way.
*/
if ((cmd == LINUX_REBOOT_CMD_POWER_OFF) && !pm_power_off)
cmd = LINUX_REBOOT_CMD_HALT;
mutex_lock(&system_transition_mutex);
switch (cmd) {
case LINUX_REBOOT_CMD_RESTART:
kernel_restart(NULL);
break;
case LINUX_REBOOT_CMD_CAD_ON:
C_A_D = 1;
break;
case LINUX_REBOOT_CMD_CAD_OFF:
C_A_D = 0;
break;
case LINUX_REBOOT_CMD_HALT:
kernel_halt();
do_exit(0);
panic("cannot halt");
case LINUX_REBOOT_CMD_POWER_OFF:
kernel_power_off();
do_exit(0);
break;
case LINUX_REBOOT_CMD_RESTART2:
ret = strncpy_from_user(&buffer[0], arg, sizeof(buffer) - 1);
if (ret < 0) {
ret = -EFAULT;
break;
}
buffer[sizeof(buffer) - 1] = '�';
kernel_restart(buffer);
break;
#ifdef CONFIG_KEXEC_CORE
case LINUX_REBOOT_CMD_KEXEC:
ret = kernel_kexec();
break;
#endif
#ifdef CONFIG_HIBERNATION
case LINUX_REBOOT_CMD_SW_SUSPEND:
ret = hibernate();
break;
#endif
default:
ret = -EINVAL;
break;
}
mutex_unlock(&system_transition_mutex);
return ret;
}
void kernel_power_off(void)
{
kernel_shutdown_prepare(SYSTEM_POWER_OFF);
if (pm_power_off_prepare)
pm_power_off_prepare();
migrate_to_reboot_cpu();
syscore_shutdown();
pr_emerg("Power down
");
kmsg_dump(KMSG_DUMP_SHUTDOWN);
machine_power_off();
} 关机命令最终会由平台相关的代码来执行。
四、CPU动态调频
早期的CPU的频率都是固定的,但是有一些极客玩家会去超频。后来CPU厂商官方支持CPU动态调频了。但是什么时候调,由谁去调,调到多少,这些问题就交给了内核。Linux内核设计了一个CPUFreq框架,此框架明确区分了各个角色,不同的角色职责不同。CPUFreq框架由3部分组成,CPUFreq Govenor、CPUFreq Core和CPUFreq Driver。Govenor是决策者,负责决定什么时候进行调频,调到多少,Driver是执行者,和具体的硬件打交道,Core是中间人,负责居中协调。一个系统可以有多个候选决策者,但是只能有一个当前决策者,每个候选决策者都向Core注册自己,用户空间可以选择哪个决策者作为当前决策者。一个系统必须有且只有一个执行者,执行者由CPU厂商开发,编译哪个平台的代码就会编译哪个执行者,此执行者会向Core注册自己。下面我们画个图来看一下CPUFreq的整体框架。
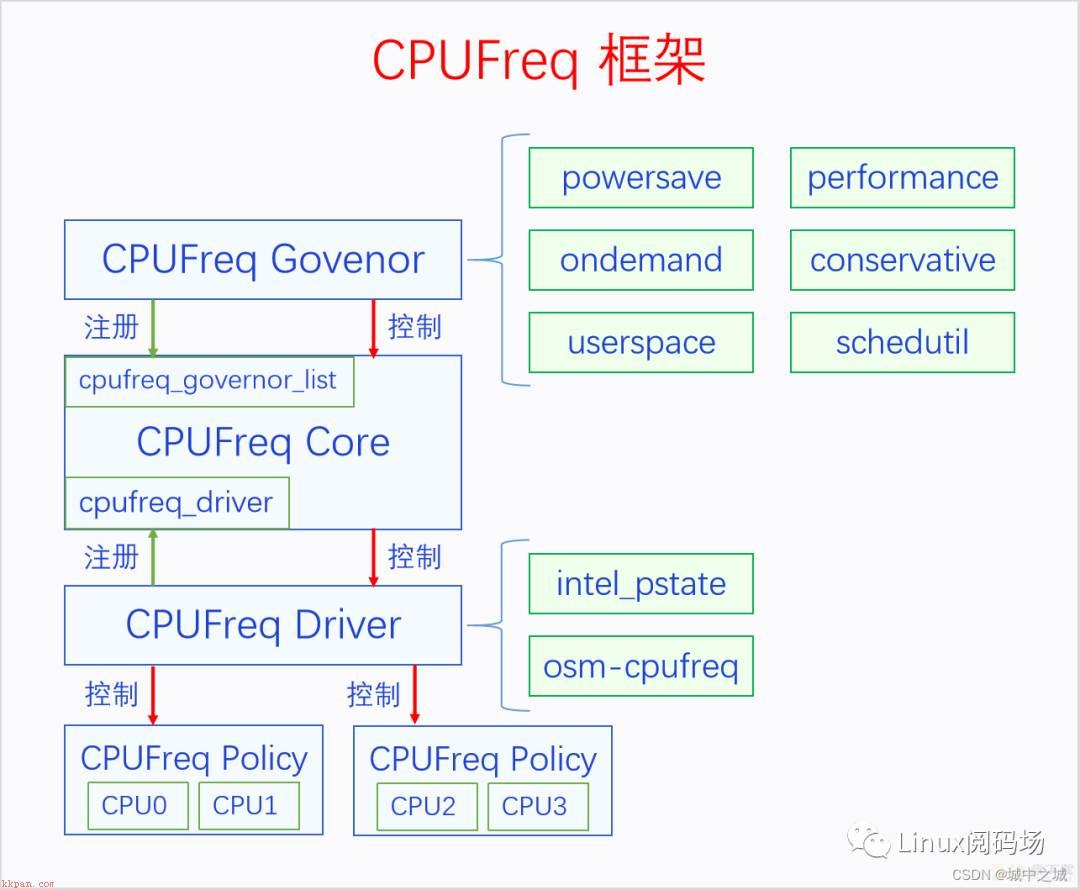
可以发现图中有一个CPUFreq Policy,这是什么意思呢?这是因为CPU调频并不能为每一个CPU单独调频,有些CPU必须作为一个整体进行调频,所以抽象出了一个CPUFreq Policy的概念,方便操作。
4.1 CPUFreq Core
Core中定义了一个全局变量cpufreq_governor_list,可以使用接口cpufreq_register_governor来注册决策者,系统中可以同时注册很多决策者,对于每个policy来说只有一个当前决策者生效。Core还定义了一个全局变量cpufreq_driver,可以使用接口cpufreq_register_driver来注册执行者,对于一个系统来说有且只能有一个决策者被注册,第二个注册的会返回错误。Core还定义全局变量cpufreq_policy_list,代表的是policy的列表,policy代表是多个必须一起改变频率的CPU的集合。
我们先来看一下决策者的定义和注册函数:
linux-src/include/linux/cpufreq.h
struct cpufreq_governor {
char name[CPUFREQ_NAME_LEN];
int (*init)(struct cpufreq_policy *policy);
void (*exit)(struct cpufreq_policy *policy);
int (*start)(struct cpufreq_policy *policy);
void (*stop)(struct cpufreq_policy *policy);
void (*limits)(struct cpufreq_policy *policy);
ssize_t (*show_seTSPeed) (struct cpufreq_policy *policy,
char *buf);
int (*store_setspeed) (struct cpufreq_policy *policy,
unsigned int freq);
struct list_head governor_list;
struct module *owner;
u8 flags;
}; linux-src/drivers/cpufreq/cpufreq.c
int cpufreq_register_governor(struct cpufreq_governor *governor)
{
int err;
if (!governor)
return -EINVAL;
if (cpufreq_disabled())
return -ENODEV;
mutex_lock(&cpufreq_governor_mutex);
err = -EBUSY;
if (!find_governor(governor->name)) {
err = 0;
list_add(&governor->governor_list, &cpufreq_governor_list);
}
mutex_unlock(&cpufreq_governor_mutex);
return err;
} 可以看到注册过程很简单,就是把决策者往list中一放就可以了。我们来看一下决策者的几个函数指针,init是在把决策者设置给policy的时候会调用,exit是在旧的决策者被替换的时候被调用。Start是在决策者开始生效的时候调用,stop是在决策者不再生效的时候调用,limits是在Core需要调频的时候会调用。
我们再来看一下决策者的定义和注册函数: linux-src/include/linux/cpufreq.h
struct cpufreq_driver {
char name[CPUFREQ_NAME_LEN];
u16 flags;
void *driver_data;
/* needed by all drivers */
int (*init)(struct cpufreq_policy *policy);
int (*verify)(struct cpufreq_policy_data *policy);
/* define one out of two */
int (*setpolicy)(struct cpufreq_policy *policy);
int (*target)(struct cpufreq_policy *policy,
unsigned int target_freq,
unsigned int relation); /* Deprecated */
int (*target_index)(struct cpufreq_policy *policy,
unsigned int index);
unsigned int (*fast_switch)(struct cpufreq_policy *policy,
unsigned int target_freq);
/*
* ->fast_switch() replacement for drivers that use an internal
* representation of performance levels and can pass hints other than
* the target performance level to the hardware.
*/
void (*adjust_perf)(unsigned int cpu,
unsigned long min_perf,
unsigned long target_perf,
unsigned long capacity);
/*
* Only for drivers with target_index() and CPUFREQ_ASYNC_NOTIFICATION
* unset.
*
* get_intermediate should return a stable intermediate frequency
* platform wants to switch to and target_intermediate() should set CPU
* to that frequency, before jumping to the frequency corresponding
* to 'index'. Core will take care of sending notifications and driver
* doesn't have to handle them in target_intermediate() or
* target_index().
*
* Drivers can return '0' from get_intermediate() in case they don't
* wish to switch to intermediate frequency for some target frequency.
* In that case core will directly call ->target_index().
*/
unsigned int (*get_intermediate)(struct cpufreq_policy *policy,
unsigned int index);
int (*target_intermediate)(struct cpufreq_policy *policy,
unsigned int index);
/* should be defined, if possible */
unsigned int (*get)(unsigned int cpu);
/* Called to update policy limits on firmware notifications. */
void (*update_limits)(unsigned int cpu);
/* optional */
int (*bios_limit)(int cpu, unsigned int *limit);
int (*online)(struct cpufreq_policy *policy);
int (*offline)(struct cpufreq_policy *policy);
int (*exit)(struct cpufreq_policy *policy);
int (*suspend)(struct cpufreq_policy *policy);
int (*resume)(struct cpufreq_policy *policy);
struct freq_attr **attr;
/* platform specific boost support code */
bool boost_enabled;
int (*set_boost)(struct cpufreq_policy *policy, int state);
/*
* Set by drivers that want to register with the energy model after the
* policy is properly initialized, but before the governor is started.
*/
void (*register_em)(struct cpufreq_policy *policy);
}; linux-src/drivers/cpufreq/cpufreq.c
int cpufreq_register_driver(struct cpufreq_driver *driver_data)
{
unsigned long flags;
int ret;
if (cpufreq_disabled())
return -ENODEV;
/*
* The cpufreq core depends heavily on the availability of device
* structure, make sure they are available before proceeding further.
*/
if (!get_cpu_device(0))
return -EPROBE_DEFER;
if (!driver_data || !driver_data->verify || !driver_data->init ||
!(driver_data->setpolicy || driver_data->target_index ||
driver_data->target) ||
(driver_data->setpolicy && (driver_data->target_index ||
driver_data->target)) ||
(!driver_data->get_intermediate != !driver_data->target_intermediate) ||
(!driver_data->online != !driver_data->offline))
return -EINVAL;
pr_debug("trying to register driver %s
", driver_data->name);
/* Protect against concurrent CPU online/offline. */
cpus_read_lock();
write_lock_irqsave(&cpufreq_driver_lock, flags);
if (cpufreq_driver) {
write_unlock_irqrestore(&cpufreq_driver_lock, flags);
ret = -EEXIST;
goto out;
}
cpufreq_driver = driver_data;
write_unlock_irqrestore(&cpufreq_driver_lock, flags);
/*
* Mark support for the scheduler's frequency invariance engine for
* drivers that implement target(), target_index() or fast_switch().
*/
if (!cpufreq_driver->setpolicy) {
static_branch_enable_cpuslocked(&cpufreq_freq_invariance);
pr_debug("supports frequency invariance");
}
if (driver_data->setpolicy)
driver_data->flags |= CPUFREQ_CONST_LOOPS;
if (cpufreq_boost_supported()) {
ret = create_boost_sysfs_file();
if (ret)
goto err_null_driver;
}
ret = subsys_interface_register(&cpufreq_interface);
if (ret)
goto err_boost_unreg;
if (unlikely(list_empty(&cpufreq_policy_list))) {
/* if all ->init() calls failed, unregister */
ret = -ENODEV;
pr_debug("%s: No CPU initialized for driver %s
", __func__,
driver_data->name);
goto err_if_unreg;
}
ret = cpuhp_setup_state_nocalls_cpuslocked(CPUHP_AP_ONLINE_DYN,
"cpufreq:online",
cpuhp_cpufreq_online,
cpuhp_cpufreq_offline);
if (ret < 0)
goto err_if_unreg;
hp_online = ret;
ret = 0;
pr_debug("driver %s up and running
", driver_data->name);
goto out;
err_if_unreg:
subsys_interface_unregister(&cpufreq_interface);
err_boost_unreg:
remove_boost_sysfs_file();
err_null_driver:
write_lock_irqsave(&cpufreq_driver_lock, flags);
cpufreq_driver = NULL;
write_unlock_irqrestore(&cpufreq_driver_lock, flags);
out:
cpus_read_unlock();
return ret;
} 可以看到注册函数也很简单,主要就是为全局变量cpufreq_driver赋值。我们来看一下执行者的函数指针,其中最重要的函数指针是target和target_index,它们是具体负责设置目标policy的频率的,target是老的接口,是为了兼容才保留下来的,现在建议使用接口target_index。
我们再来看一下policy的定义和注册函数: linux-src/include/linux/cpufreq.h
struct cpufreq_policy {
/* CPUs sharing clock, require sw coordination */
cpumask_var_t cpus; /* Online CPUs only */
cpumask_var_t related_cpus; /* Online + Offline CPUs */
cpumask_var_t real_cpus; /* Related and present */
unsigned int shared_type; /* ACPI: ANY or ALL affected CPUs
should set cpufreq */
unsigned int cpu; /* cpu managing this policy, must be online */
struct clk *clk;
struct cpufreq_cpuinfo cpuinfo;/* see above */
unsigned int min; /* in kHz */
unsigned int max; /* in kHz */
unsigned int cur; /* in kHz, only needed if cpufreq
* governors are used */
unsigned int suspend_freq; /* freq to set during suspend */
unsigned int policy; /* see above */
unsigned int last_policy; /* policy before unplug */
struct cpufreq_governor *governor; /* see below */
void *governor_data;
char last_governor[CPUFREQ_NAME_LEN]; /* last governor used */
struct work_struct update; /* if update_policy() needs to be
* called, but you're in IRQ context */
struct freq_constraints constraints;
struct freq_qos_request *min_freq_req;
struct freq_qos_request *max_freq_req;
struct cpufreq_frequency_table *freq_table;
enum cpufreq_table_sorting freq_table_sorted;
struct list_head policy_list;
struct kobject kobj;
struct completion kobj_unregister;
/*
* The rules for this semaphore:
* - Any routine that wants to read from the policy structure will
* do a down_read on this semaphore.
* - Any routine that will write to the policy structure and/or may take away
* the policy altogether (eg. CPU hotplug), will hold this lock in write
* mode before doing so.
*/
struct rw_semaphore rwsem;
/*
* Fast switch flags:
* - fast_switch_possible should be set by the driver if it can
* guarantee that frequency can be changed on any CPU sharing the
* policy and that the change will affect all of the policy CPUs then.
* - fast_switch_enabled is to be set by governors that support fast
* frequency switching with the help of cpufreq_enable_fast_switch().
*/
bool fast_switch_possible;
bool fast_switch_enabled;
/*
* Set if the CPUFREQ_GOV_STRICT_TARGET flag is set for the current
* governor.
*/
bool strict_target;
/*
* Preferred average time interval between consecutive invocations of
* the driver to set the frequency for this policy. To be set by the
* scaling driver (0, which is the default, means no preference).
*/
unsigned int transition_delay_us;
/*
* Remote DVFS flag (Not added to the driver structure as we don't want
* to access another structure from scheduler hotpath).
*
* Should be set if CPUs can do DVFS on behalf of other CPUs from
* different cpufreq policies.
*/
bool dvfs_possible_from_any_cpu;
/* Cached frequency lookup from cpufreq_driver_resolve_freq. */
unsigned int cached_target_freq;
unsigned int cached_resolved_idx;
/* Synchronization for frequency transitions */
bool transition_ongoing; /* Tracks transition status */
spinlock_t transition_lock;
wait_queue_head_t transition_wait;
struct task_struct *transition_task; /* Task which is doing the transition */
/* cpufreq-stats */
struct cpufreq_stats *stats;
/* For cpufreq driver's internal use */
void *driver_data;
/* Pointer to the cooling device if used for thermal mitigation */
struct thermal_cooling_device *cdev;
struct notifier_block nb_min;
struct notifier_block nb_max;
}; linux-src/drivers/cpufreq/cpufreq.c
static int cpufreq_online(unsigned int cpu)
{
struct cpufreq_policy *policy;
bool new_policy;
unsigned long flags;
unsigned int j;
int ret;
pr_debug("%s: bringing CPU%u online
", __func__, cpu);
/* Check if this CPU already has a policy to manage it */
policy = per_cpu(cpufreq_cpu_data, cpu);
if (policy) {
WARN_ON(!cpumask_test_cpu(cpu, policy->related_cpus));
if (!policy_is_inactive(policy))
return cpufreq_add_policy_cpu(policy, cpu);
/* This is the only online CPU for the policy. Start over. */
new_policy = false;
down_write(&policy->rwsem);
policy->cpu = cpu;
policy->governor = NULL;
up_write(&policy->rwsem);
} else {
new_policy = true;
policy = cpufreq_policy_alloc(cpu);
if (!policy)
return -ENOMEM;
}
if (!new_policy && cpufreq_driver->online) {
ret = cpufreq_driver->online(policy);
if (ret) {
pr_debug("%s: %d: initialization failed
", __func__,
__LINE__);
goto out_exit_policy;
}
/* Recover policy->cpus using related_cpus */
cpumask_copy(policy->cpus, policy->related_cpus);
} else {
cpumask_copy(policy->cpus, cpumask_of(cpu));
/*
* Call driver. From then on the cpufreq must be able
* to accept all calls to ->verify and ->setpolicy for this CPU.
*/
ret = cpufreq_driver->init(policy);
if (ret) {
pr_debug("%s: %d: initialization failed
", __func__,
__LINE__);
goto out_free_policy;
}
/*
* The initialization has succeeded and the policy is online.
* If there is a problem with its frequency table, take it
* offline and drop it.
*/
ret = cpufreq_table_validate_and_sort(policy);
if (ret)
goto out_offline_policy;
/* related_cpus should at least include policy->cpus. */
cpumask_copy(policy->related_cpus, policy->cpus);
}
down_write(&policy->rwsem);
/*
* affected cpus must always be the one, which are online. We aren't
* managing offline cpus here.
*/
cpumask_and(policy->cpus, policy->cpus, cpu_online_mask);
if (new_policy) {
for_each_cpu(j, policy->related_cpus) {
per_cpu(cpufreq_cpu_data, j) = policy;
add_cpu_dev_symlink(policy, j, get_cpu_device(j));
}
policy->min_freq_req = kzalloc(2 * sizeof(*policy->min_freq_req),
GFP_KERNEL);
if (!policy->min_freq_req) {
ret = -ENOMEM;
goto out_destroy_policy;
}
ret = freq_qos_add_request(&policy->constraints,
policy->min_freq_req, FREQ_QOS_MIN,
FREQ_QOS_MIN_DEFAULT_VALUE);
if (ret < 0) {
/*
* So we don't call freq_qos_remove_request() for an
* uninitialized request.
*/
kfree(policy->min_freq_req);
policy->min_freq_req = NULL;
goto out_destroy_policy;
}
/*
* This must be initialized right here to avoid calling
* freq_qos_remove_request() on uninitialized request in case
* of errors.
*/
policy->max_freq_req = policy->min_freq_req + 1;
ret = freq_qos_add_request(&policy->constraints,
policy->max_freq_req, FREQ_QOS_MAX,
FREQ_QOS_MAX_DEFAULT_VALUE);
if (ret < 0) {
policy->max_freq_req = NULL;
goto out_destroy_policy;
}
blocking_notifier_call_chain(&cpufreq_policy_notifier_list,
CPUFREQ_CREATE_POLICY, policy);
}
if (cpufreq_driver->get && has_target()) {
policy->cur = cpufreq_driver->get(policy->cpu);
if (!policy->cur) {
ret = -EIO;
pr_err("%s: ->get() failed
", __func__);
goto out_destroy_policy;
}
}
/*
* Sometimes boot loaders set CPU frequency to a value outside of
* frequency table present with cpufreq core. In such cases CPU might be
* unstable if it has to run on that frequency for long duration of time
* and so its better to set it to a frequency which is specified in
* freq-table. This also makes cpufreq stats inconsistent as
* cpufreq-stats would fail to register because current frequency of CPU
* isn't found in freq-table.
*
* Because we don't want this change to effect boot process badly, we go
* for the next freq which is >= policy->cur ('cur' must be set by now,
* otherwise we will end up setting freq to lowest of the table as 'cur'
* is initialized to zero).
*
* We are passing target-freq as "policy->cur - 1" otherwise
* __cpufreq_driver_target() would simply fail, as policy->cur will be
* equal to target-freq.
*/
if ((cpufreq_driver->flags & CPUFREQ_NEED_INITIAL_FREQ_CHECK)
&& has_target()) {
unsigned int old_freq = policy->cur;
/* Are we running at unknown frequency ? */
ret = cpufreq_frequency_table_get_index(policy, old_freq);
if (ret == -EINVAL) {
ret = __cpufreq_driver_target(policy, old_freq - 1,
CPUFREQ_RELATION_L);
/*
* Reaching here after boot in a few seconds may not
* mean that system will remain stable at "unknown"
* frequency for longer duration. Hence, a BUG_ON().
*/
BUG_ON(ret);
pr_info("%s: CPU%d: Running at unlisted initial frequency: %u KHz, changing to: %u KHz
",
__func__, policy->cpu, old_freq, policy->cur);
}
}
if (new_policy) {
ret = cpufreq_add_dev_interface(policy);
if (ret)
goto out_destroy_policy;
cpufreq_stats_create_table(policy);
write_lock_irqsave(&cpufreq_driver_lock, flags);
list_add(&policy->policy_list, &cpufreq_policy_list);
write_unlock_irqrestore(&cpufreq_driver_lock, flags);
/*
* Register with the energy model before
* sched_cpufreq_governor_change() is called, which will result
* in rebuilding of the sched domains, which should only be done
* once the energy model is properly initialized for the policy
* first.
*
* Also, this should be called before the policy is registered
* with cooling Framework.
*/
if (cpufreq_driver->register_em)
cpufreq_driver->register_em(policy);
}
ret = cpufreq_init_policy(policy);
if (ret) {
pr_err("%s: Failed to initialize policy for cpu: %d (%d)
",
__func__, cpu, ret);
goto out_destroy_policy;
}
up_write(&policy->rwsem);
kobject_uevent(&policy->kobj, KOBJ_ADD);
if (cpufreq_thermal_control_enabled(cpufreq_driver))
policy->cdev = of_cpufreq_cooling_register(policy);
pr_debug("initialization complete
");
return 0;
out_destroy_policy:
for_each_cpu(j, policy->real_cpus)
remove_cpu_dev_symlink(policy, get_cpu_device(j));
up_write(&policy->rwsem);
out_offline_policy:
if (cpufreq_driver->offline)
cpufreq_driver->offline(policy);
out_exit_policy:
if (cpufreq_driver->exit)
cpufreq_driver->exit(policy);
out_free_policy:
cpufreq_policy_free(policy);
return ret;
} Policy代表的是必须得一起调节频率的CPU的集合,对于物理CPU来说,并不是每个核都可以单独调节频率的。系统中有多少个policy是和CPU的具体情况有关。
4.2 Govener介绍
系统中一个存在6个决策者,下面我们一一介绍一下。
1.performance
performance的策略非常简单,就是一直把CPU的频率设置为最大值。代码如下:
linux-src/drivers/cpufreq/cpufreq_performance.c
static struct cpufreq_governor cpufreq_gov_performance = {
.name = "performance",
.owner = THIS_MODULE,
.flags = CPUFREQ_GOV_STRICT_TARGET,
.limits = cpufreq_gov_performance_limits,
};
static void cpufreq_gov_performance_limits(struct cpufreq_policy *policy)
{
pr_debug("setting to %u kHz
", policy->max);
__cpufreq_driver_target(policy, policy->max, CPUFREQ_RELATION_H);
} 2.powersave
powersave的策略也非常简单,就是一直把CPU的频率设置为最小值。代码如下:
linux-src/drivers/cpufreq/cpufreq_powersave.c
static struct cpufreq_governor cpufreq_gov_powersave = {
.name = "powersave",
.limits = cpufreq_gov_powersave_limits,
.owner = THIS_MODULE,
.flags = CPUFREQ_GOV_STRICT_TARGET,
};
static void cpufreq_gov_powersave_limits(struct cpufreq_policy *policy)
{
pr_debug("setting to %u kHz
", policy->min);
__cpufreq_driver_target(policy, policy->min, CPUFREQ_RELATION_L);
} 3.conservative
Conservative,包括模式,总是把频率往policy的最大值和最小值之间调整。代码如下:
linux-src/drivers/cpufreq/cpufreq_conservative.c
static struct dbs_governor cs_governor = {
.gov = CPUFREQ_DBS_GOVERNOR_INITIALIZER("conservative"),
.kobj_type = { .default_attrs = cs_attributes },
.gov_dbs_update = cs_dbs_update,
.alloc = cs_alloc,
.free = cs_free,
.init = cs_init,
.exit = cs_exit,
.start = cs_start,
}; linux-src/drivers/cpufreq/cpufreq_governor.h
#define CPUFREQ_DBS_GOVERNOR_INITIALIZER(_name_)
{
.name = _name_,
.flags = CPUFREQ_GOV_DYNAMIC_SWITCHING,
.owner = THIS_MODULE,
.init = cpufreq_dbs_governor_init,
.exit = cpufreq_dbs_governor_exit,
.start = cpufreq_dbs_governor_start,
.stop = cpufreq_dbs_governor_stop,
.limits = cpufreq_dbs_governor_limits,
} linux-src/drivers/cpufreq/cpufreq_governor.c
void cpufreq_dbs_governor_limits(struct cpufreq_policy *policy)
{
struct policy_dbs_info *policy_dbs;
/* Protect gov->gdbs_data against cpufreq_dbs_governor_exit() */
mutex_lock(&gov_dbs_data_mutex);
policy_dbs = policy->governor_data;
if (!policy_dbs)
goto out;
mutex_lock(&policy_dbs->update_mutex);
cpufreq_policy_apply_limits(policy);
gov_update_sample_delay(policy_dbs, 0);
mutex_unlock(&policy_dbs->update_mutex);
out:
mutex_unlock(&gov_dbs_data_mutex);
} linux-src/include/linux/cpufreq.h
static inline void cpufreq_policy_apply_limits(struct cpufreq_policy *policy)
{
if (policy->max < policy->cur)
__cpufreq_driver_target(policy, policy->max, CPUFREQ_RELATION_H);
else if (policy->min > policy->cur)
__cpufreq_driver_target(policy, policy->min, CPUFREQ_RELATION_L);
} 4.userspace
Userspace,按照用户空间设置的值进行调节,代码如下:
linux-src/drivers/cpufreq/cpufreq_userspace.c
static struct cpufreq_governor cpufreq_gov_userspace = {
.name = "userspace",
.init = cpufreq_userspace_policy_init,
.exit = cpufreq_userspace_policy_exit,
.start = cpufreq_userspace_policy_start,
.stop = cpufreq_userspace_policy_stop,
.limits = cpufreq_userspace_policy_limits,
.store_setspeed = cpufreq_set,
.show_setspeed = show_speed,
.owner = THIS_MODULE,
};
static void cpufreq_userspace_policy_limits(struct cpufreq_policy *policy)
{
unsigned int *setspeed = policy->governor_data;
mutex_lock(&userspace_mutex);
pr_debug("limit event for cpu %u: %u - %u kHz, currently %u kHz, last set to %u kHz
",
policy->cpu, policy->min, policy->max, policy->cur, *setspeed);
if (policy->max < *setspeed)
__cpufreq_driver_target(policy, policy->max, CPUFREQ_RELATION_H);
else if (policy->min > *setspeed)
__cpufreq_driver_target(policy, policy->min, CPUFREQ_RELATION_L);
else
__cpufreq_driver_target(policy, *setspeed, CPUFREQ_RELATION_L);
mutex_unlock(&userspace_mutex);
} 5.ondemand
Ondemand,按需调整,默认运行在较低频率,系统负载增大时就运行在高频率,代码如下: linux-src/drivers/cpufreq/cpufreq_ondemand.c
static struct dbs_governor od_dbs_gov = {
.gov = CPUFREQ_DBS_GOVERNOR_INITIALIZER("ondemand"),
.kobj_type = { .default_attrs = od_attributes },
.gov_dbs_update = od_dbs_update,
.alloc = od_alloc,
.free = od_free,
.init = od_init,
.exit = od_exit,
.start = od_start,
}; 6.schedutil
Schedutil,根据CPU使用率动态调整频率,代码如下: linux-src/kernel/sched/cpufreq_schedutil.c
struct cpufreq_governor schedutil_gov = {
.name = "schedutil",
.owner = THIS_MODULE,
.flags = CPUFREQ_GOV_DYNAMIC_SWITCHING,
.init = sugov_init,
.exit = sugov_exit,
.start = sugov_start,
.stop = sugov_stop,
.limits = sugov_limits,
};
static void sugov_limits(struct cpufreq_policy *policy)
{
struct sugov_policy *sg_policy = policy->governor_data;
if (!policy->fast_switch_enabled) {
mutex_lock(&sg_policy->work_lock);
cpufreq_policy_apply_limits(policy);
mutex_unlock(&sg_policy->work_lock);
}
sg_policy->limits_changed = true;
} 4.3 Driver介绍
在x86上只有一个执行者,叫做intel_pstate,我们来看一下它的代码实现:
linux-src/drivers/cpufreq/intel_pstate.c
static struct cpufreq_driver intel_pstate = {
.flags = CPUFREQ_CONST_LOOPS,
.verify = intel_pstate_verify_policy,
.setpolicy = intel_pstate_set_policy,
.suspend = intel_pstate_suspend,
.resume = intel_pstate_resume,
.init = intel_pstate_cpu_init,
.exit = intel_pstate_cpu_exit,
.offline = intel_pstate_cpu_offline,
.online = intel_pstate_cpu_online,
.update_limits = intel_pstate_update_limits,
.name = "intel_pstate",
};
static int intel_pstate_set_policy(struct cpufreq_policy *policy)
{
struct cpudata *cpu;
if (!policy->cpuinfo.max_freq)
return -ENODEV;
pr_debug("set_policy cpuinfo.max %u policy->max %u
",
policy->cpuinfo.max_freq, policy->max);
cpu = all_cpu_data[policy->cpu];
cpu->policy = policy->policy;
mutex_lock(&intel_pstate_limits_lock);
intel_pstate_update_perf_limits(cpu, policy->min, policy->max);
if (cpu->policy == CPUFREQ_POLICY_PERFORMANCE) {
/*
* NOHZ_FULL CPUs need this as the governor callback may not
* be invoked on them.
*/
intel_pstate_clear_update_util_hook(policy->cpu);
intel_pstate_max_within_limits(cpu);
} else {
intel_pstate_set_update_util_hook(policy->cpu);
}
if (hwp_active) {
/*
* When hwp_boost was active before and dynamically it
* was turned off, in that case we need to clear the
* update util hook.
*/
if (!hwp_boost)
intel_pstate_clear_update_util_hook(policy->cpu);
intel_pstate_hwp_set(policy->cpu);
}
mutex_unlock(&intel_pstate_limits_lock);
return 0;
}
static int __init intel_pstate_init(void)
{
const struct x86_cpu_id *id;
int rc;
if (boot_cpu_data.x86_vendor != X86_VENDOR_INTEL)
return -ENODEV;
id = x86_match_cpu(hwp_support_ids);
if (id) {
bool hwp_forced = intel_pstate_hwp_is_enabled();
if (hwp_forced)
pr_info("HWP enabled by BIOS
");
else if (no_load)
return -ENODEV;
copy_cpu_funcs(&core_funcs);
/*
* Avoid enabling HWP for processors without EPP support,
* because that means incomplete HWP implementation which is a
* corner case and supporting it is generally problematic.
*
* If HWP is enabled already, though, there is no choice but to
* deal with it.
*/
if ((!no_hwp && boot_cpu_has(X86_FEATURE_HWP_EPP)) || hwp_forced) {
hwp_active++;
hwp_mode_bdw = id->driver_data;
intel_pstate.attr = hwp_cpufreq_attrs;
intel_cpufreq.attr = hwp_cpufreq_attrs;
intel_cpufreq.flags |= CPUFREQ_NEED_UPDATE_LIMITS;
intel_cpufreq.adjust_perf = intel_cpufreq_adjust_perf;
if (!default_driver)
default_driver = &intel_pstate;
if (boot_cpu_has(X86_FEATURE_HYBRID_CPU))
intel_pstate_cppc_set_cpu_scaling();
goto hwp_cpu_matched;
}
pr_info("HWP not enabled
");
} else {
if (no_load)
return -ENODEV;
id = x86_match_cpu(intel_pstate_cpu_ids);
if (!id) {
pr_info("CPU model not supported
");
return -ENODEV;
}
copy_cpu_funcs((struct pstate_funcs *)id->driver_data);
}
if (intel_pstate_msrs_not_valid()) {
pr_info("Invalid MSRs
");
return -ENODEV;
}
/* Without HWP start in the passive mode. */
if (!default_driver)
default_driver = &intel_cpufreq;
hwp_cpu_matched:
/*
* The Intel pstate driver will be ignored if the platform
* firmware has its own power management modes.
*/
if (intel_pstate_platform_pwr_mgmt_exists()) {
pr_info("P-states controlled by the platform
");
return -ENODEV;
}
if (!hwp_active && hwp_only)
return -ENOTSUPP;
pr_info("Intel P-state driver initializing
");
all_cpu_data = vzalloc(array_size(sizeof(void *), num_possible_cpus()));
if (!all_cpu_data)
return -ENOMEM;
intel_pstate_request_control_from_smm();
intel_pstate_sysfs_expose_params();
mutex_lock(&intel_pstate_driver_lock);
rc = intel_pstate_register_driver(default_driver);
mutex_unlock(&intel_pstate_driver_lock);
if (rc) {
intel_pstate_sysfs_remove();
return rc;
}
if (hwp_active) {
const struct x86_cpu_id *id;
id = x86_match_cpu(intel_pstate_cpu_ee_disable_ids);
if (id) {
set_power_ctl_ee_state(false);
pr_info("Disabling energy efficiency optimization
");
}
pr_info("HWP enabled
");
} else if (boot_cpu_has(X86_FEATURE_HYBRID_CPU)) {
pr_warn("Problematic setup: Hybrid processor with disabled HWP
");
}
return 0;
}
device_initcall(intel_pstate_init); 五、CPU休闲
CPU在无进程可执行的情况下会进入idle状态,idle状态的CPU可以选择进入低功耗模式以节省能源。不同的低功耗模式被统称为C-state,ACPI定义的有C0、C1、C2、C3、C4、C5、C6这几种模式,CPU厂商可以选择实现C0–Cn,n >= 3。下面是各种模式的定义:
C0:CPU的正常工作模式,CPU处于100%运行状态。
C1:通过软件停止CPU内部主时钟;总线接口单元和APIC仍然保持全速运行。
C2:通过硬件停止CPU内部主时钟;总线接口单元和APIC仍然保持全速运行。
C3:停止所有CPU内部时钟。
C4:降低CPU电压。
C5:大幅降低CPU电压并关闭内存高速缓存。
C6:将CPU内部电压降低至任何值,包括0V。
那么谁来决定CPU该进入哪一级的idle状态,又该谁去执行这个决定呢?为此Linux设计了CPUIdle框架,区分了不同的角色。决策者负责决定该进入哪一级idle状态,执行者负责去执行,Core负责居中调节,下面我们画个图来看一下。

可以看到系统能同时注册多个决策者,但是却只能注册一个执行者。和CPUFreq不同的是每个CPU可以单独调节自己的低功耗状态,所以Driver直接调节的就是CPU。
5.1 CPUIdle Core
Core定义了一个全局变量cpuidle_governors,是所有决策者的列表,可以通过接口cpuidle_register_governor注册决策者,全局变量cpuidle_curr_governor代表当前决策者。Core还定义了cpuidle_curr_driver,代表当前执行者,可以通过接口cpuidle_register_driver来注册执行者,一个系统只能注册一个执行者,后面注册的会返回错误。
下面我们看一下决策者的定义和注册函数: linux-src/include/linux/cpuidle.h
struct cpuidle_governor {
char name[CPUIDLE_NAME_LEN];
struct list_head governor_list;
unsigned int rating;
int (*enable) (struct cpuidle_driver *drv,
struct cpuidle_device *dev);
void (*disable) (struct cpuidle_driver *drv,
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
struct cpuidle_device *dev,
bool *stop_tick);
void (*reflect) (struct cpuidle_device *dev, int index);
}; linux-src/drivers/cpuidle/governor.c
int cpuidle_register_governor(struct cpuidle_governor *gov)
{
int ret = -EEXIST;
if (!gov || !gov->select)
return -EINVAL;
if (cpuidle_disabled())
return -ENODEV;
mutex_lock(&cpuidle_lock);
if (cpuidle_find_governor(gov->name) == NULL) {
ret = 0;
list_add_tail(&gov->governor_list, &cpuidle_governors);
if (!cpuidle_curr_governor ||
!strncasecmp(param_governor, gov->name, CPUIDLE_NAME_LEN) ||
(cpuidle_curr_governor->rating < gov->rating &&
strncasecmp(param_governor, cpuidle_curr_governor->name,
CPUIDLE_NAME_LEN)))
cpuidle_switch_governor(gov);
}
mutex_unlock(&cpuidle_lock);
return ret;
} 下面我们再来看一下执行者的定义和注册函数:
linux-src/include/linux/cpuidle.h
struct cpuidle_driver {
const char *name;
struct module *owner;
/* used by the cpuidle framework to setup the broadcast timer */
unsigned int bctimer:1;
/* states array must be ordered in decreasing power consumption */
struct cpuidle_state states[CPUIDLE_STATE_MAX];
int state_count;
int safe_state_index;
/* the driver handles the cpus in cpumask */
struct cpumask *cpumask;
/* preferred governor to switch at register time */
const char *governor;
}; linux-src/drivers/cpuidle/driver.c
int cpuidle_register_driver(struct cpuidle_driver *drv)
{
struct cpuidle_governor *gov;
int ret;
spin_lock(&cpuidle_driver_lock);
ret = __cpuidle_register_driver(drv);
spin_unlock(&cpuidle_driver_lock);
if (!ret && !strlen(param_governor) && drv->governor &&
(cpuidle_get_driver() == drv)) {
mutex_lock(&cpuidle_lock);
gov = cpuidle_find_governor(drv->governor);
if (gov) {
cpuidle_prev_governor = cpuidle_curr_governor;
if (cpuidle_switch_governor(gov) < 0)
cpuidle_prev_governor = NULL;
}
mutex_unlock(&cpuidle_lock);
}
return ret;
} 5.2 决策者介绍
CPUIdle中默认有两个决策者,ladder和menu。ladder是梯子的意思,CPU 随着idle的时间其睡眠程度逐渐加深,适用于固定tick。menu是菜单的意思,预估一个CPU idle的时间,然后CPU一步到位地处于某种睡眠状态,适用于动态tick。下面我们分别来看看它们的实现。
1.ladder
linux-src/drivers/cpuidle/governors/ladder.c
static struct cpuidle_governor ladder_governor = {
.name = "ladder",
.rating = 10,
.enable = ladder_enable_device,
.select = ladder_select_state,
.reflect = ladder_reflect,
};
static int ladder_select_state(struct cpuidle_driver *drv,
struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct ladder_device_state *last_state;
int last_idx = dev->last_state_idx;
int first_idx = drv->states[0].flags & CPUIDLE_FLAG_POLLING ? 1 : 0;
s64 latency_req = cpuidle_governor_latency_req(dev->cpu);
s64 last_residency;
/* Special case when user has set very strict latency requirement */
if (unlikely(latency_req == 0)) {
ladder_do_selection(dev, ldev, last_idx, 0);
return 0;
}
last_state = &ldev->states[last_idx];
last_residency = dev->last_residency_ns - drv->states[last_idx].exit_latency_ns;
/* consider promotion */
if (last_idx < drv->state_count - 1 &&
!dev->states_usage[last_idx + 1].disable &&
last_residency > last_state->threshold.promotion_time_ns &&
drv->states[last_idx + 1].exit_latency_ns <= latency_req) {
last_state->stats.promotion_count++;
last_state->stats.demotion_count = 0;
if (last_state->stats.promotion_count >= last_state->threshold.promotion_count) {
ladder_do_selection(dev, ldev, last_idx, last_idx + 1);
return last_idx + 1;
}
}
/* consider demotion */
if (last_idx > first_idx &&
(dev->states_usage[last_idx].disable ||
drv->states[last_idx].exit_latency_ns > latency_req)) {
int i;
for (i = last_idx - 1; i > first_idx; i--) {
if (drv->states[i].exit_latency_ns <= latency_req)
break;
}
ladder_do_selection(dev, ldev, last_idx, i);
return i;
}
if (last_idx > first_idx &&
last_residency < last_state->threshold.demotion_time_ns) {
last_state->stats.demotion_count++;
last_state->stats.promotion_count = 0;
if (last_state->stats.demotion_count >= last_state->threshold.demotion_count) {
ladder_do_selection(dev, ldev, last_idx, last_idx - 1);
return last_idx - 1;
}
}
/* otherwise remain at the current state */
return last_idx;
} 2.menu
linux-src/drivers/cpuidle/governors/menu.c
static struct cpuidle_governor menu_governor = {
.name = "menu",
.rating = 20,
.enable = menu_enable_device,
.select = menu_select,
.reflect = menu_reflect,
};
static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
bool *stop_tick)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
s64 latency_req = cpuidle_governor_latency_req(dev->cpu);
unsigned int predicted_us;
u64 predicted_ns;
u64 interactivity_req;
unsigned int nr_iowaiters;
ktime_t delta, delta_tick;
int i, idx;
if (data->needs_update) {
menu_update(drv, dev);
data->needs_update = 0;
}
/* determine the expected residency time, round up */
delta = tick_nohz_get_sleep_length(&delta_tick);
if (unlikely(delta < 0)) {
delta = 0;
delta_tick = 0;
}
data->next_timer_ns = delta;
nr_iowaiters = nr_iowait_cpu(dev->cpu);
data->bucket = which_bucket(data->next_timer_ns, nr_iowaiters);
if (unlikely(drv->state_count <= 1 || latency_req == 0) ||
((data->next_timer_ns < drv->states[1].target_residency_ns ||
latency_req < drv->states[1].exit_latency_ns) &&
!dev->states_usage[0].disable)) {
/*
* In this case state[0] will be used no matter what, so return
* it right away and keep the tick running if state[0] is a
* polling one.
*/
*stop_tick = !(drv->states[0].flags & CPUIDLE_FLAG_POLLING);
return 0;
}
/* Round up the result for half microseconds. */
predicted_us = div_u64(data->next_timer_ns *
data->correction_factor[data->bucket] +
(RESOLUTION * DECAY * NSEC_PER_USEC) / 2,
RESOLUTION * DECAY * NSEC_PER_USEC);
/* Use the lowest expected idle interval to pick the idle state. */
predicted_ns = (u64)min(predicted_us,
get_typical_interval(data, predicted_us)) *
NSEC_PER_USEC;
if (tick_nohz_tick_stopped()) {
/*
* If the tick is already stopped, the cost of possible short
* idle duration misprediction is much higher, because the CPU
* may be stuck in a shallow idle state for a long time as a
* result of it. In that case say we might mispredict and use
* the known time till the closest timer event for the idle
* state selection.
*/
if (predicted_ns < TICK_NSEC)
predicted_ns = data->next_timer_ns;
} else {
/*
* Use the performance multiplier and the user-configurable
* latency_req to determine the maximum exit latency.
*/
interactivity_req = div64_u64(predicted_ns,
performance_multiplier(nr_iowaiters));
if (latency_req > interactivity_req)
latency_req = interactivity_req;
}
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
*/
idx = -1;
for (i = 0; i < drv->state_count; i++) {
struct cpuidle_state *s = &drv->states[i];
if (dev->states_usage[i].disable)
continue;
if (idx == -1)
idx = i; /* first enabled state */
if (s->target_residency_ns > predicted_ns) {
/*
* Use a physical idle state, not busy polling, unless
* a timer is going to trigger soon enough.
*/
if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) &&
s->exit_latency_ns <= latency_req &&
s->target_residency_ns <= data->next_timer_ns) {
predicted_ns = s->target_residency_ns;
idx = i;
break;
}
if (predicted_ns < TICK_NSEC)
break;
if (!tick_nohz_tick_stopped()) {
/*
* If the state selected so far is shallow,
* waking up early won't hurt, so retain the
* tick in that case and let the governor run
* again in the next iteration of the loop.
*/
predicted_ns = drv->states[idx].target_residency_ns;
break;
}
/*
* If the state selected so far is shallow and this
* state's target residency matches the time till the
* closest timer event, select this one to avoid getting
* stuck in the shallow one for too long.
*/
if (drv->states[idx].target_residency_ns < TICK_NSEC &&
s->target_residency_ns <= delta_tick)
idx = i;
return idx;
}
if (s->exit_latency_ns > latency_req)
break;
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
/*
* Don't stop the tick if the selected state is a polling one or if the
* expected idle duration is shorter than the tick period length.
*/
if (((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
predicted_ns < TICK_NSEC) && !tick_nohz_tick_stopped()) {
*stop_tick = false;
if (idx > 0 && drv->states[idx].target_residency_ns > delta_tick) {
/*
* The tick is not going to be stopped and the target
* residency of the state to be returned is not within
* the time until the next timer event including the
* tick, so try to correct that.
*/
for (i = idx - 1; i >= 0; i--) {
if (dev->states_usage[i].disable)
continue;
idx = i;
if (drv->states[i].target_residency_ns <= delta_tick)
break;
}
}
}
return idx;
} 5.3 Driver介绍
在x86上只有一个执行者叫pseries_idle。
linux-src/drivers/cpuidle/cpuidle-pseries.c
static struct cpuidle_driver pseries_idle_driver = {
.name = "pseries_idle",
.owner = THIS_MODULE,
};
static int __init pseries_processor_idle_init(void)
{
int retval;
retval = pseries_idle_probe();
if (retval)
return retval;
pseries_cpuidle_driver_init();
retval = cpuidle_register(&pseries_idle_driver, NULL);
if (retval) {
printk(KERN_DEBUG "Registration of pseries driver failed.
");
return retval;
}
retval = cpuhp_setup_state_nocalls(CPUHP_AP_ONLINE_DYN,
"cpuidle/pseries:online",
pseries_cpuidle_cpu_online, NULL);
WARN_ON(retval < 0);
retval = cpuhp_setup_state_nocalls(CPUHP_CPUIDLE_DEAD,
"cpuidle/pseries:DEAD", NULL,
pseries_cpuidle_cpu_dead);
WARN_ON(retval < 0);
printk(KERN_DEBUG "pseries_idle_driver registered
");
return 0;
}
device_initcall(pseries_processor_idle_init); 六、电源质量管理
我们前面讲了很多省电机制,但是也不能一味地省电。毕竟我们用计算机的目的是为了用计算机,而不是为了省电。省电也不能牺牲太大的性能,从而影响了用户体验。所以内核里开发PM QoS模块,专门用来处理电源管理的服务质量问题。PM QoS是一个框架,面向顾客(内核和进程),它提供了请求接口,顾客可以请求系统某一方面的性能不能低于某个标准;面向省电机制,它提供了查询接口,省电机制在进行省电的时候要通过这个接口进行查询,然后省电的同时也要满足这个标准。
PM QoS把对某一项性能的最低要求抽象为一个约束,所有顾客都可以对某个约束发出请求,也可以修改请求、移除请求,PM QoS会把能满足所有要求的数值发给省电机制。约束可以分为两类,系统级约束和设备级约束,系统级约束针对的是系统的性能,设备级约束针对的是一个设备。内核中的顾客可以直接调用接口函数来添加约束请求,用户空间的顾客可以通过设备节点文件来添加约束请求。
6.1 系统级约束
系统级约束有两个,CPU频率和CPU延迟。CPU频率代表的是CPU运行时的性能,频率越高,性能越强,功耗也越大。CPU延迟是CPU Idle之后从低功耗状态恢复到运行的时间,CPU idle之后可以处于不同的低功耗状态,状态越深越省电,但是恢复的延迟越大。
下面我们首先看一下CPU频率约束的定义和请求函数:
linux-src/include/linux/pm_qos.h
struct freq_constraints {
struct pm_qos_constraints min_freq;
struct blocking_notifier_head min_freq_notifiers;
struct pm_qos_constraints max_freq;
struct blocking_notifier_head max_freq_notifiers;
};
struct pm_qos_constraints {
struct plist_head list;
s32 target_value; /* Do not change to 64 bit */
s32 default_value;
s32 no_constraint_value;
enum pm_qos_type type;
struct blocking_notifier_head *notifiers;
};
struct freq_qos_request {
enum freq_qos_req_type type;
struct plist_node pnode;
struct freq_constraints *qos;
};
enum freq_qos_req_type {
FREQ_QOS_MIN = 1,
FREQ_QOS_MAX,
}; 这是频率约束的相关定义。
linux-src/kernel/power/qos.c
int freq_qos_add_request(struct freq_constraints *qos,
struct freq_qos_request *req,
enum freq_qos_req_type type, s32 value)
{
int ret;
if (IS_ERR_OR_NULL(qos) || !req)
return -EINVAL;
if (WARN(freq_qos_request_active(req),
"%s() called for active request
", __func__))
return -EINVAL;
req->qos = qos;
req->type = type;
ret = freq_qos_apply(req, PM_QOS_ADD_REQ, value);
if (ret < 0) {
req->qos = NULL;
req->type = 0;
}
return ret;
}
int freq_qos_apply(struct freq_qos_request *req,
enum pm_qos_req_action action, s32 value)
{
int ret;
switch(req->type) {
case FREQ_QOS_MIN:
ret = pm_qos_update_target(&req->qos->min_freq, &req->pnode,
action, value);
break;
case FREQ_QOS_MAX:
ret = pm_qos_update_target(&req->qos->max_freq, &req->pnode,
action, value);
break;
default:
ret = -EINVAL;
}
return ret;
} 这是CPU频率约束的请求函数。
linux-src/kernel/power/qos.c
s32 freq_qos_read_value(struct freq_constraints *qos,
enum freq_qos_req_type type)
{
s32 ret;
switch (type) {
case FREQ_QOS_MIN:
ret = IS_ERR_OR_NULL(qos) ?
FREQ_QOS_MIN_DEFAULT_VALUE :
pm_qos_read_value(&qos->min_freq);
break;
case FREQ_QOS_MAX:
ret = IS_ERR_OR_NULL(qos) ?
FREQ_QOS_MAX_DEFAULT_VALUE :
pm_qos_read_value(&qos->max_freq);
break;
default:
WARN_ON(1);
ret = 0;
}
return ret;
} CPUFreq模块会通过接口freq_qos_read_value来读取CPU频率约束,以便在动态调频的时候也满足最低性能要求。
下面我们首先看一下CPU延迟约束的定义和请求函数:
linux-src/include/linux/pm_qos.h
struct pm_qos_constraints {
struct plist_head list;
s32 target_value; /* Do not change to 64 bit */
s32 default_value;
s32 no_constraint_value;
enum pm_qos_type type;
struct blocking_notifier_head *notifiers;
};
struct pm_qos_request {
struct plist_node node;
struct pm_qos_constraints *qos;
}; 这是CPU延迟约束的定义。
linux-src/kernel/power/qos.c
void cpu_latency_qos_add_request(struct pm_qos_request *req, s32 value)
{
if (!req)
return;
if (cpu_latency_qos_request_active(req)) {
WARN(1, KERN_ERR "%s called for already added request
", __func__);
return;
}
trace_pm_qos_add_request(value);
req->qos = &cpu_latency_constraints;
cpu_latency_qos_apply(req, PM_QOS_ADD_REQ, value);
}
static void cpu_latency_qos_apply(struct pm_qos_request *req,
enum pm_qos_req_action action, s32 value)
{
int ret = pm_qos_update_target(req->qos, &req->node, action, value);
if (ret > 0)
wake_up_all_idle_cpus();
} 这是CPU延迟约束的请求函数
linux-src/kernel/power/qos.c
s32 cpu_latency_qos_limit(void)
{
return pm_qos_read_value(&cpu_latency_constraints);
}
s32 pm_qos_read_value(struct pm_qos_constraints *c)
{
return READ_ONCE(c->target_value);
} CPUIdle模块会通过这个接口来读取对CPU延迟的最小要求。
6.2 设备级约束
暂略
linux-src/drivers/base/power/qos.c
七、总结回顾
通过本文我们对计算机的电源管理有了一个基本的了解,下面我们再看图回忆一下:
电源管理分为电源状态管理和省电管理两个重要组成部分。电源状态管理是对计算机的电源状态进行管理,包括睡眠、休眠、关机、重启等。省电管理是内核中的一些省电机制,可以很好的帮我们节省电力。光一味地省电也不行,还得考虑计算机的性能,所以电源管理中还有PM QoS来保证电源管理的服务质量,使得计算机的运行还要满足一定的性能需求。
参考文献:
https://lwn.net/Kernel/Index/#Power_management https://lwn.net/Kernel/Index/#Software_suspend https://lwn.net/Kernel/Index/#Power_management-Opportunistic_suspend https://lwn.net/Kernel/Index/#cpufreq https://lwn.net/Kernel/Index/#Power_management-cpuidle
https://man7.org/linux/man-pages/man2/reboot.2.html
http://www.wowotech.net/sort/pm_subsyste
加载全部内容