HDFS HA架构以及源码引导
作者:快盘下载 人气:HA体系架构
相关知识介绍
HDFS master/slave架构,HDFS节点分为Namenode节点和DataNode节点。NameNode存有HDFS的元数据:主要由FSImage和EditLog组成。FSImage保存有文件的目录、分块ID、文件权限等,EditLog保存有对HDFS的操作记录。DataNode存放分块的数据,并采用CRC循环校验方式对本地的数据进行校验,DataNode周期性向NameNode汇报本机的信息。
NameNode单点故障:HDFS只有一个NameNode节点,当NameNode崩溃后,整个HDFS集群随之崩溃。
HDFS HA:为了解决NameNode的单点故障,为NameNode保存一个热备,这样namenode共有两个:Active Namenode、Standby Namenode。集群使用的时候,用的是Active Namenode,而Standby Namenode存放的是Active Namenode的热备。
Standby NN的功能
作为Active NN的热备,当Active NN崩溃的时候,快速的切换成Active NN充当以前Secondary NN的角色:合并FSImage和EditLog,并将FSImage传回给Active NN。Standby NN周期性监控共享存储中EditLog的状态变化,当监控到变化的时候,Standby NN会读取该Log,并更新本机上的FSImage,之后再启动一个线程,将该FSImage增量更新到Active NN上。 |
|---|
存储共享:共享HDFS的操作日志Editlog,可以使用Quorum Journal Manager (QJM)或者NFS作为存储共享模块。
脑裂:集群中有两个NN同时控制集群。当Active NN失效时,StandbyNN切换成Active NN,当原来的Active NN活过来时,集群中就有两个Active NN了,这时就有两个NN可以控制集群,这就是脑裂。
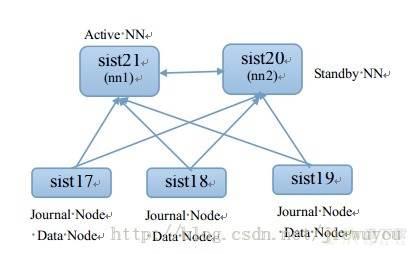
HA手动模式架构
Active NN 和Standby NN之间通过JN共享EditLog。QJM负责向JN写EditLog。HA架构如下所示。

搭建过程参考http://blog.csdn.net/jiewuyou/article/details/21779247
搭建好后的效果如下:
QJM/Qurom Journal Manager的架构如图所示。QJM 采用Paxos 算法 ,大概思路是,有2N+1个节点作为JN ,当有N+1个JN更新成功时,就算更新成功。QJM是一个轻量级的共享存储,可以和DN部署在一个节点上。Quorum JornalManager运行在Active NameNode上,用于管理JournalNode,并向JN更新EditLog。

[1] Active NN向JN中更新EditLog的时候,是并行写的,和HDFS中block的流式写是有区别的
[2] Standby NN感知到EditLog中有更新时,会从JN中选择一个存有该更新的JN,并读取该更新
隔离(Fencing)
隔离(Fencing)是为了防止脑裂,就是保证在任何时候HDFS只有一个Active NN,主要包括三个方面:
Ø 共享存储fencing,确保只有一个NN可以写入edits。QJM中每一个JournalNode中均有一个epochnumber,匹配epochnumber的QJM才有权限更新JN。当NN由standby状态切换成active状态时,会重新生成一个epoch number,并更新JN中的epochnumber,以至于以前的ActiveNN中的QJM中的epoch number和JN的epochnumber不匹配,故而原ActiveNN上的QJM没法往JN中写入数据(后面会介绍源码),即形成了fencing
Ø 客户端fencing,确保只有一个NN可以响应客户端的请求。
Ø DataNodefencing,确保只有一个NN可以向DN下发命令,譬如删除块,复制块,等等。
QJM的Fencing方案只能让原来的Active NN失去对JN的写权限,但是原来的Active NN还是可以响应客户端的请求,对DN进行读。配置dfs.ha.fencing.methods可以指定Fencing的方法。Hadoop公共库中有两种Fencing实现:sshfence、shell
sshfence:ssh到原Active NN上,结束进程(通过tcp端口号定位进程pid,该方法比jps命令更准确)。
shell - run an arbitraryshell command to fencethe Active NameNode,即执行一个用户事先定义的shell命令(脚本)完成隔离。
你也可以重写org.apache.hadoop.ha.NodeFencer文件,生成自己的Fencing方法。
自动故障切换AutomaticFailover
自动切换架构

来自:http://zh.hortonworks.com/blog/namenode-high-availability-in-hdp-2-0/
配置:http://hadoop.apache.org/docs/r2.3.0/hadoop-yarn/hadoop-yarn-site/HDFSHighAvailabilityWithQJM.html
Automated Failover 当active namenode崩溃的时候,自动将standby namenode切换成active namenode。
Hot Standby Namenode Standby NN维持着HDFS的元数据,可以在Failover的时候快速的进行切换。实现原理:
1) DN向两个NN同时发送心跳汇报
2) Standby NN会实时的读取共享存储中EditLog里面的日志
Full Stack Resiliency 在使用Failover的时候,HDP已经证实不会影响其上作业的运行。
ZooKeeper FailoverController (ZKFC)用于决定何时进行failover,共有两个ZKFC进程,分别运行在两个NN上。它会实时监控NN的状态,一旦Active NN不能提供服务的时候,就进行failover。
源码
Qjournal
Qjournal包
org.apache.hadoop.hdfs.qjournal:这个包是测试JournalNode用的
MiniJournalCluster | |
|---|---|
QJMTestUtil | |
TestMiniJournalCluster | |
TestNNWithQJM |
org.apache.hadoop.hdfs.qjournal.client:客户端,提供对qjournal的相关操作
QuromJournalManager | 运行在NameNode上,用来管理JNs,并向JNs更新EditLog。 |
|---|---|
QuorumOutputStream | 实现接口EditLogOutputStream,用于向JN写数据 |
SegmentRecoveryComparator | 可以比较各个JN的Log Segment,看哪个JN的质量更高,以选择同步用的Log Segment源。例如在NN切换成Active的时候,JN的Log Segment可能不一致,通过该类就可以选择Log Segment同步源,其他JN需要同步该Log Segment同步源 |
接口AsyncLogger | 远程异步通信接口 |
IPCLoggerChannel | AsyncLogger的实现。通过Hadoop IPC和JN远程通信的管道 |
org.apache.hadoop.hdfs.qjournal.protocol:保存有QuorumJournalManager和JournalNode之间的通信协议接口
接口QJournalProtocol | QJM、JNs之间的通信协议,该协议用于发送EditLog,以及节点间的coordinating recovery |
|---|---|
RequestInfo | 请求信息 |
JournalOutOfSyncException | |
JournalNotFormattedException | Exception indicating that a call has been made to a JournalNode which is not yet formatted. |
org.apache.hadoop.hdfs.qjournal.protocolPB
org.apache.hadoop.hdfs.qjournal.server:保存有qjournal相关服务
GetJournalEditServlet | This servlet is used in two cases: · The QuorumJournalManager, when reading edits, fetches the edit streams from the journal nodes. · During edits synchronization, one journal node will fetch edits from another journal node. |
|---|---|
JNStorage | JN数据存储的实现 |
Journal | JN可以和不同的集群通信,这是通过Journal实现的。尽管这些Journal是完全独立的,但他们运行在一个JVM里面的 |
JournalMetrics | The server-side metrics for a journal from the JournalNode's perspective. |
JournalNode | The JournalNode is a daemon which allows namenodes using the QuorumJournalManager to log and retrieve edits stored remotely. It is a thin wrapper around a local edit log directory with the addition of facilities to participate in the quorum protocol. |
JournalNodeHttpServer | 封装有HTTP服务,由Journal服务启动 |
JournalNodeRpcServer | JN上的RPC实现类 |
RPC
上面在代码中提到了RPC,QJM的RPC主要就一个协议类:QuorumJournalManager与多个JournalNode通信的协议QJournalProtocol。那么RPC的通信双方的实体类分别是哪个呢?客户端(QuorumJournalManager)是QJournalProtocolTranslatorPB;服务器端(JournalNode)是JournalNodeRpcServer。
org.apache.hadoop.ha

org.apache.hadoop.hdfs.server.namenode.ha

过程分析
ActiveNN启动过程
NN进入Active NN时,会执行ActiveState.enterState(),调用过程如下,后面的一系列过程可以参考StandbyNN切换成Active的过程
NameNode(Configuration conf, NamenodeRole role) ActiveState.enterState() NameNode.startActiveServices() FSNamesystem.startActiveServices() |
|---|
EditLog格式化
Actice NN 上的FSImage初始化完成后,需要格式化EditLog。
FSNamesystem. loadFSImage() FSImage.format() FSEditLog. formatNonFileJournals () QuorumJournalManager.format(NamespaceInfo nsInfo) |
|---|
相对于Paxos 算法,format操作是比较特殊的,要求所有的JN返回都成功时才行,因为它相当于是做了个初始化的工作。而在后面更新数据的过程中,只要大多数success response就认为这次写成功了。
Automatic Failover过程
共两个ZKFC,分别运行在两个NN上,同时ZookeeprService维持有Active NN的锁。Active NN上的ZKFC会监控该NN的状态并管理HA状态,一旦Actice NN失效的时候,ZKFC会从Zookeeper Service上释放Active NN锁。
Standby NN上的ZKFC也会监控该NN的状态,并尝试从Zookeeper Service上获取Active NN的锁。当Active NN失去该锁的时候,StandbyNN上的ZKFC会接管该锁,并将 Standby NN的状态切换成Active NN。
相关源码
package org.apache.hadoop.ha HealthMonitor.java ZKFailoverController.java 接口ZKFCProtocol.java ZKFCRpcServer.java |
|---|
1.监控NN状态
调用过程:
ZKFailoverCtroller.run() ZKFailoverCtroller. doRun() ZKFailoverController.initHM() HealthMonitor.start(); MonitorDaemon.start() MonitorDaemon.run(); |
|---|
分析MonitorDaemon.run()
public void run() {
while (shouldRun) {
try {
//等待HAServiceProtocol可用
loopUntilConnected();
//监控服务状态,并进行相应处理
doHealthChecks();
} catch (InterruptedException ie) {
Preconditions.checkState(!shouldRun,
"Interrupted but still supposed to run");
}
}
} doHealthChecks()经过一系列的调用后,会调用NameNode.monitorHealth(),用于监控NameNode可用状态。当NN没有资源可用时,抛出异常。
2. 监控到服务不可用时
上面提到,当服务不可用的时候,会抛出异常。
监测到异常State.SERVICE_UNHEALTHY时
HealthMonitor.doHealthChecks() enterState(State.SERVICE_UNHEALTHY); |
|---|
监测到异常 State.SERVICE_NOT_RESPONDING)时
HealthMonitor.doHealthChecks() enterState(State. SERVICE_HEALTHY); |
|---|
在enterState()里面,会经过一系列回调函数
HealthMonitor.enterState() HealthCallbacks. enteredState(); ZKFailoverController.recheckElectability() ActiveStandbyElector. quitElection(true); ActiveStandbyElector. tryDeleteOwnBreadCrumbNode() |
|---|
之后,Active NN上的ZKFC会失去ZookeeperService上的Active NN锁。而Standby NN上的ZKFC一直在尝试获取该锁,此时,Standby NN上的ZKFC就获得了该锁,当Standby NN上的ZKFC获取Active NN锁的时候,会将NN切换成Actice。
Standby切换成Actice过程
参考:http://yanbohappy.sinaapp.com/?p=205
函数调用过程
NameNode.setStateInternal(final HAContext context, final HAState s)//状态转换 ActiveState. enterState() |
|---|
接下来就该看看一个StandbyNN由Standby变成Active时,需要执行哪些操作:
1) fencing原来Active NN的写。
2) recover in-progress logs。原来Active NN写EditLog过程中发生了主从切换,那么处在不同JournalNode上的EditLog的数据可能不一致,需要把不同JournalNode上的EditLog同步一致,并且finalized。(这个过程类似于HDFS append中的recover lease的过程)
3) startLogSegment。让切换成Active的NN拥有写日志功能。
1. fencing原来Active NN的写
基于QJM的HA不需要处理fencing问题。这是怎么做到的呢?解决这个问题靠的是epoch number,这个和Paxos算法中选主(master election)所做的工作类似。QJM和JN均保存有一个唯一的epoch number,只有拥有这个epoch number的NameNode才可以往Journal Node写数据。系统初始化、或者Standby NameNode切换成Active Namenode时,都会执行QourumJournalManager.recoverUnfinalizedSegments()。在生成新的epochnumber后QourumJournalManager会通过RPC将该epochnumber发送给各个JournalNode。
一系列的“擦屁股”的操作结束之后,当原来的Active NameNode想写日志时,因为epoch number没法匹配journal node的epoch number,这样写操作被拒绝。
当Active 和Standby NN 发生主从切换时,原来的StandbyNN需要执行:
NameNode.setStateInternal(final HAContext context, final HAState s)//状态转换 ActiveState. enterState() NameNode.startActiveServices() FSNamesystem.startActiveServices() FSEditLog.recoverUnclosedStreams() JournalSet.recoverUnfinalizedSegments() QourumJournalManager.recoverUnfinalizedSegment() |
|---|
这个过程说白了就是给原来的ActiveNN擦屁股,也可以算作是Standby要接管qjournal写权利的开始。这里面就出现了我们所说的brain-split的问题,Standby NN怎么保证原来的Active NN已经不再往qjournal上写数据了。看看QourumJournalManager.recoverUnfinalizedSegment()的实现过程:
// Fence any previous writers, and obtain a unique epoch number for write-access to the journal nodes.Returns:the new, unique epoch number
public void recoverUnfinalizedSegments() throws IOException {
Preconditions.checkState(!isActiveWriter, "already active writer");
LOG.info("Starting recovery process for unclosed journal segments...");
//这句话解决了brain-split问题,也就是fencing writer
Map<AsyncLogger, NewEpochResponseProto> resps = createNewUniqueEpoch();
LOG.info("Successfully started new epoch " + loggers.getEpoch());
if (LOG.isDebugEnabled()) {
LOG.debug("newEpoch(" + loggers.getEpoch() + ") responses:
" +
QuorumCall.mapToString(resps));
}
//找出最后一块edit log segment,因为只有最后一块有可能是不完整的。
long mostRecentSegmentTxId = Long.MIN_VALUE;
for (NewEpochResponseProto r : resps.values()) {
if (r.hasLastSegmentTxId()) {
mostRecentSegmentTxId = Math.max(mostRecentSegmentTxId,
r.getLastSegmentTxId());
}
}
// On a completely fresh system, none of the journals have any
// segments, so there's nothing to recover.
if (mostRecentSegmentTxId != Long.MIN_VALUE) {
//把不完整的log segment恢复完整
recoverUnclosedSegment(mostRecentSegmentTxId);
}
isActiveWriter = true;
} Epoch解决了我们所说的问题,StandbyNN向每个JournalNode发送getJournalState RPC请求,JN返回自己的lastPromisedEpoch。QuorumJournalManager收到大多数JN返回的lastPromisedEpoch,在其中选择最大的一个,然后加1作为当前QJM的epoch,同时通过发送newEpoch RPC把这个新的epoch写到qjournal上。因为在这之后每次QuorumJournalManager在向qjournal执行写相关操作(startLogSegment(),logEdits(), finalizedLogSegment()等)的时候,都要把自己的epoch作为参数传递过去,写相关操作到达每个JournalNode端会比较如果传过来的epoch如果小于JournalNode端存储的lastPromisedEpoch,那么这次写相关操作会被拒绝。如果大多数JournalNode都拒绝了这次写相关操作,这次操作就失败了。回到我们目前的逻辑中,在主从切换时,原来的Standby NN把epoch+1了之后,原来的Active NN的epoch就肯定比这个小了,那么如果它再向qjournal写日志就会被拒绝。因为qjournal不接收比lastPromisedEpoch小的QJM写日志。
看看JN收到newEpoch RPC之后怎么办:JN检查来自QJM的这个epoch和自己存储的lastPromisedEpoch:如果来自writer的epoch小于lastPromisedEpoch,那么说明不允许这个writer向JNs写数据了,抛出异常,writer端收到异常response,那么达不到大多数的successresponse,就不会有写qjournal的权限了。(其实这个过程就是Paxos算法里面选主的过程)。
2. recover in-progress logs
接着上面的代码,Standby已经通过createNewUniqueEpoch()来fencing原来的Active,这个RPC请求除了会返回epoch,还会返回最后一个logsegment的txid。因为只有最后一个log segment可能需要恢复。这个recover算法就是Paxos算法的一个实例(instance),目的是使得分布在不同JN上的log segment的数据达成一致。
接下来就开始recoverUnclosedSegment()恢复算法。
private void recoverUnclosedSegment(long segmentTxId) throws IOException {
Preconditions.checkArgument(segmentTxId > 0);
LOG.info("Beginning recovery of unclosed segment starting at txid " +
segmentTxId);
// Step 1. Prepare recovery
//QJM向JNs问segmentTxId对应的segment的长度和finalized/in-progress状况;JNs返回这些信息。(对应Paxos算法的Phase 1a和Phase 1b)
QuorumCall<AsyncLogger,PrepareRecoveryResponseProto> prepare =
loggers.prepareRecovery(segmentTxId);
Map<AsyncLogger, PrepareRecoveryResponseProto> prepareResponses=
loggers.waitForWriteQuorum(prepare, prepareRecoveryTimeoutMs,
"prepareRecovery(" + segmentTxId + ")");
LOG.info("Recovery prepare phase complete. Responses:
" +
QuorumCall.mapToString(prepareResponses));
//在每个JN的返回信息中通过SegmentRecoveryComparator比较,选择其中最好的一个log segment作为后面同步log的标准。
//如何选择更好的Log segment后面有详细解释。
Entry<AsyncLogger, PrepareRecoveryResponseProto> bestEntry = Collections.max(
prepareResponses.entrySet(), SegmentRecoveryComparator.INSTANCE);
AsyncLogger bestLogger = bestEntry.getKey();
PrepareRecoveryResponseProto bestResponse = bestEntry.getValue();
// Log the above decision, check invariants.
if (bestResponse.hasAcceptedInEpoch()) {
LOG.info("Using already-accepted recovery for segment " +
"starting at txid " + segmentTxId + ": " +
bestEntry);
} else if (bestResponse.hasSegmentState()) {
LOG.info("Using longest log: " + bestEntry);
} else {
//prepareRecovery RPC没有返回任何指定txid的segment,原因可能如下:
//有3个JNs: JN1,JN2,JN3。原来的Active NN 在JN1上开始写segment 101,
//然后原来Active NN挂了,主从切换,此时segment 101在JN2和JN3上并不存在,
//newEpoch RPC,因为我们看到了JN1上的segment 101,所以决定recover的是segment 101
//在prepareRecovery之前,JN1挂了,那么prepareRecovery RPC只能发向JN2和JN3了,RPC返回的结果是没有segment 101
//这种情况下是不需要recover的,因为segment 101并没有写成功(没有达到大多数)
for (PrepareRecoveryResponseProto resp : prepareResponses.values()) {
assert !resp.hasSegmentState() :
"One of the loggers had a response, but no best logger " +
"was found.";
}
LOG.info("None of the responders had a log to recover: " +
QuorumCall.mapToString(prepareResponses));
return;
}
SegmentStateProto logToSync = bestResponse.getSegmentState();
assert segmentTxId == logToSync.getStartTxId();
// Sanity check: none of the loggers should be aware of a higher
// txid than the txid we intend to truncate to
for (Map.Entry<AsyncLogger, PrepareRecoveryResponseProto> e :
prepareResponses.entrySet()) {
AsyncLogger logger = e.getKey();
PrepareRecoveryResponseProto resp = e.getValue();
if (resp.hasLastCommittedTxId() &&
resp.getLastCommittedTxId() > logToSync.getEndTxId()) {
throw new AssertionError("Decided to synchronize log to " + logToSync +
" but logger " + logger + " had seen txid " +
resp.getLastCommittedTxId() + " committed");
}
}
//同步log的数据源JN找到后,构造URL用于其他JN读取EditLog(JN端有HTTP server通过servlet形式提供HTTP读)
URL syncFromUrl = bestLogger.buildURLToFetchLogs(segmentTxId);
//向JNs发送acceptRecovery RPC请求(对应Paxos算法的Phase 2a)
//JN收到这个acceptRecovery RPC之后,使自己的log与syncFromUrl同步,并持久化这个logsegment和epoch
//如果收到大多数的JNs的success response,那么这个同步操作成功。(对应Paxos算法的Phase 2b)
QuorumCall<AsyncLogger,Void> accept = loggers.acceptRecovery(logToSync, syncFromUrl);
loggers.waitForWriteQuorum(accept, acceptRecoveryTimeoutMs,
"acceptRecovery(" + TextFormat.shortDebugString(logToSync) + ")");
// If one of the loggers above missed the synchronization step above, but
// we send a finalize() here, that's OK. It validates the log before
// finalizing. Hence, even if it is not "in sync", it won't incorrectly
// finalize.
//EditLog既然已经同步完了,那么就应该正常finalized了。
QuorumCall<AsyncLogger, Void> finalize =
loggers.finalizeLogSegment(logToSync.getStartTxId(), logToSync.getEndTxId());
loggers.waitForWriteQuorum(finalize, finalizeSegmentTimeoutMs,
String.format("finalizeLogSegment(%s-%s)",
logToSync.getStartTxId(),
logToSync.getEndTxId()));
} 代码中留给我们一个问题,就是什么样的log segment是更好的,在recover的过程中被选为同步源呢。详细的设计可以参考Todd写的<<Quorum-Journal Design>> https://issues.apache.org/jira/secure/attachment/12547598/qjournal-design.pdf 的2.9和2.10。在代码中的实现是SegmentRecoveryComparator类。
简单描述下原理就是:有finalized的不用in-progress的;如果有多个finalized必须length一致;没有finalized的看谁的epoch更大;如果前面的都一样就看谁的最后一个txid更大。
在<<Quorum-Journal Design>>中有具体的例子。我看完这块之后感觉和HDFS append的block recover过程中选择同步源的思路有异曲同工之妙。
经历了上面的QourumJournalManager.recoverUnfinalizedSegment()过程,不完整的logsegment都是完整的了,接下来就是调用EditLogTailer.doTailEdits(),原来Standby NN先去和原来ActiveNN同步EditLog,然后把EditLog执行,这时两台NN内存数据才真正一致。这里会调用QuorumJournalManager.selectInputStreams()从JNs中读取 EditLog。而且目前HDFS中只有finalizededit log才能被Standby NN读取并执行。在Standby NN从JNs读取EditLog时,首先向所有的JN节点发送getEditLogManifest() RPC去读取大于某一txid并且已经finalizededit log segment,收到大多数返回success,则把这些log segment整合成一个RedundantEditLogInputStream,然后Standby NN只要向其中的一台JN读取数据就行了。
至此原来的Standby NN所做的擦屁股的工作就结束了,那么它就正式变成了Active NN,接下来就是正常的记录日志的工作了。
3. startLogSegment
也是初始化QuorumOutputStream的过程。
NameNode.startActiveServices() FSNamesystem.startActiveServices() FSEditLog.openForWrite() FSEditLog.startLogSegmentAndWriteHeaderTxn() FSEditLog.startLogSegment() JournalSet.startLogSegment()//返回值是QuorumOutputStream JournalSet.startLogSegment() QuorumJournalManager.startLogSegment() |
|---|
QJM向JNs发送startLogSegmentRPC调用,如果收到多数success response则成功,用这个AsynaLogSet构造QuorumOutputStream用于写log。
Active NN更新EditLog过程
1. 初始化QuorumOutputStream
在ActiveState.enterState()阶段已经完成,参考3.4.3
2. 更新EditLog
通过下面的调用把Log写到QuorumOutputStream的doublebuffer里面。由QuorumOutputStream实现更新。
org.apache.hadoop.hdfs.server.namenode.FSEditLog.logEdit() org.apache.hadoop.hdfs.qjournal.client.QuorumOutputStream.write() |
|---|
3. 同步Log
FSEditLog.logEdit() FSEditLog.logSync() EditLogOutputStream.flush() QuorumOutputStream.flushAndSync() |
|---|
flushAndSync()通过AsyncLoggerSet.sendEdits()调用Journal RPC把对应的日志写到JNs,同样是大多数successresponse即认为成功。如果大多数返回失败的话,这次logSync操作失败,那么NameNode会abort,因为没法正常写日志了。
client选择ActiceNN
实现类 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
功能 帮助Client选择哪个节点是主节点
说明 A FailoverProxyProvider implementation which allows one to configuretwo URIs to connect to during fail-over. The first configured address is triedfirst, and on a fail-over event the other address is tried.
算法1. getActiveNN() |
|---|
输入:nn1、nn2。 输出:ActiveNN 开始: 1. ActiveNN=null 2. IF isConnective(nn1) andisActive(nn1)THEN 3. ActiveNN=nn1 4. ELSE 5. IF isConnective(nn2) andisActive(nn2)THEN 6. ActiveNN=nn2 7. END IF 8. END ELSE 9. END IF 结束 |
配置:
<property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> |
|---|
Standby NN启动时同步Active NN元数据的过程
Active NN启动后,Standby NN可以通过这两个脚本启动
bin/hdfs namenode -bootstrapStandby sbin/hadoop-daemon.sh start namenode |
|---|
第一个脚本用于初始化StandbyNN,其功能如下:
[1] 和nn1通信,获取namespace metadata和checkpointedfsimage;
[2] 从JN中获取EditLog
但是脚本会在下列情况下失效:JN没有初始化成功,不能提供EditLog。
相关的实现类:
org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby |
|---|
调用过程
NameNode. createNameNode() BootstrapStandby.run(toolArgs, conf) ToolRunner.run(BootstrapStandby, argv); BootstrapStandby.run() BootstrapStandby .doRun()//该函数负责bootstrapStandby过程 TransferFsImage.downloadImageToStorage();//下载FSImage |
|---|
注意:FSImage中封装了EditLog,HA中EditLog的存储空间在JN中。
Standby NN更新
实现类:org.apache.hadoop.hdfs.server.namenode.ha.StandbyCheckpointer
说明:Threadwhich runs inside the NN when it's in Standby state, periodically waking up totake a checkpoint of the namespace. When it takes a checkpoint, it saves it toits local storage and then uploads it to the remote NameNode.
该类里面封装了线程CheckpointerThread
CheckpointerThread.run() CheckpointerThread.doWork() CheckpointerThread.doCheckpoint()//检测是否需要进行更新 |
|---|
当检测到更新的时候,会将EditLog更新下载到本地同时进行合并成FSImage,并将最新的FSImage增量更新到Active NN上。
CheckpointerThread.doCheckpoint()//检测是否需要进行更新 TransferFsImage.uploadImageFromStorage( ) activeNNAddress, myNNAddress,namesystem.getFSImage().getStorage(), txid); |
|---|
参考资料
[1] HDFS High Availability Using the Quorum JournalManager
[2] HDFS 体系结构
[3] Hadoop 2.0 NameNode HA和Federation实践
[4] 基于QJM/Qurom Journal Manager/Paxos的HDFS HA原理及代码分析
[5] Hadoop 2.0中单点故障解决方案总结
[6] Paxos算法
加载全部内容