Keepalived高可用服务解决方案
作者:快盘下载 人气:[TOC]
文章目录
(1) Keepalive 高可用解决方案
0x00 快速入门
答:高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低到最小程度。(简单说就是:保证服务不间断地运行)
系统故障分类:
硬件故障:设计缺陷、wearout(损耗)、自然灾害、不可抗力等等软件故障:设计缺陷集群类型:
LB : LVS / nginx (http/upstream,stream / upstrem)HA 高可用性 SPoF : SinglePointofFailure,高可用的是“服务”并且资源组成一个高可用服务的“组件”(vip/nginx process shared storage)HPC 高性能计算(High Performance Computing)1)高可用集群的衡量标准 要保证集群服务100%时间永远完全可用,几乎可以说是一件不可能完成的任务,通常用平均无故障时间(MTTF)来度量系统的可靠性,用平均故障维修时间(MTTR)来度量系统的可维护性。MTBF代表着平均故障间隔时间(Mean Time Between Failures)它也与MTTR有相关关系;
可用性被定义为:HA = MTTF/(MTTF+MTTR)*100%。系统可用性的公式:HA = MTBF/(MTBF+MTTR)(0,1), 95%几个9(指标):99%,…,99.999%,99.9999%具体HA衡量标准:

WeiyiGeek.衡量标准
补充:提升系统高用性的解决方案之降低MTTR手段就是冗余redundant
2)高可用集群实现原理 高可用集群主要实现自动侦测(Auto-Detect)故障、自动切换/故障转移(FailOver)和自动恢复(FailBack)。 简单来说就是用高可用集群软件实现故障检查和故障转移(故障/备份主机切换)的自动化,当然像负载均衡、DNS分发也可提供高可性。
自动侦测(Auto-Detect)/ 故障检查 自动侦测阶段由主机上的软件通过冗余侦测线,经由复杂的监听程序逻辑判断,来相互侦测对方运行的情况。 常用的方法是:集群各节点间通过心跳信息判断节点是否出现故障。自动切换/故障转移(FailOver) 自动切换阶段某一主机如果确认对方故障,则正常主机除继续进行原来的任务,还将依据各种容错备援模式接管预先设定的备援作业程序,并进行后续的程序及服务。 通俗地说,即当A无法为客户服务时,系统能够自动地切换,使B能够及时地顶上继续为客户提供服务,且客户感觉不到这个为他提供服务的对象已经更换。自动恢复/故障回转(FailBack) 自动恢复阶段在正常主机代替故障主机工作后,故障主机可离线进行修复工作。在故障主机修复后,透过冗余通讯线与原正常主机连线,自动切换回修复完成的主机上。其他关注点 答:如果集群没有对其进行Fecning/Stonith隔离前,可以进行相关配置(without_quorum_policy),有如下配置选项:
1、stop:直接停止服务; 2、ignore:忽略,以前运行什么服务现在还运行什么(双节点集群需要配置该选项); 3、Freeze:冻结,保持事先建立的连接,但不再接收新的请求; 4、suicide:kill掉服务。
脑裂:是因为集群分裂导致的,集群中有节点因为处理器忙或者其他原因暂时停止响应时,与其他节点间的心跳出现故障,但这些节点还处于active状态,其他节点可能误认为该节点”已死”,从而争夺共享资源(如共享存储)的访问权,分裂为两部分独立节点。
脑裂后果:这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。脑裂解决:上面3-1-1、3-1-2的方法也能一定程度上解决脑裂的问题,但完全解决还需要资源隔离(Fencing)。资源隔离(Fencing):当不能确定某个节点的状态时,通过fencing把对方干掉,确保共享资源被完全释放,前提是必须要有可靠的fence设备。 节点级别:STONITH(shoot the other node in the head,爆头硬件方式),直接控制故障节点的电源,绝对彻底。 资源级别:例如:FC SAN switch(软件方式)可以实现在存储资源级别拒绝某节点的访问
3) 高可用集群工作模型
Active/Passive:主备模型; 一个活动主节点,另一个不活动作为备用节点,当主节点故障,转移到备节点,这时备节点就成为了主节点。备节点完全冗余,造成一定浪费Active/Active:双主模型; 两个节点都是活动的,两个节点运行两个不同的服务,也互为备用节点。也可以提供同一个服务,比如ipvs,前端基于DNS轮询。这种模型可以使用比较均衡的主机配置,不会造成浪费。N+1: N个活动主节点N个服务,一个备用节点,需要额外的备用节点必须能够代替任何主节点,当任何主节点故障时,备节点能够负责它的角色对外提供相应的服务N+M : N个活动主节点,M个备用节点。像上面的N+1模型,一个备用节点可能无法提供足够的备用冗余能力,备用节点的数量M是成本和可靠性要求之间的折衷。(其他说法N-M: N个节点M个服务, N>M, 活动节点为N, 备用节点为N-M。)N-to-1 : 与N+1一样,也是N个活动主节点,一个备用节点;不同是的备用节点成为主节点只是暂时的,当原来故障的节点修复后,必须回转才能正常工作N-to-N : N个主节点N个备用节点。这是A/A双主和N + M模型的组合,N节点都有服务,如果一个坏了,剩下的每个节点都可以作为替代提供服务4)高可用集群架构层次 这一层主要是正在运行在物理主机上的服务,高可用集群相关的软件运行在各主机上,集群资源也是在各主机上。
Messaging(消息) and Membership Layer(成员关系)信息传递层,传递集群信息的一种机制,通过监听UDP 694号端口,可通过单播、组播、广播的方式,实时快速传递信息,传递的内容为高可用集群的集群事务,例如:心跳信息,资源事务信息等等,只负责传递信息,不负责信息的计算和比较。成员关系(Membership)层,这层最重要的作用是主节点(DC)通过Cluster Consensus Menbership Service(CCM或者CCS)这种服务由Messaging层提供的信息,来产生一个完整的成员关系。这层主要实现承上启下的作用,承上将下层产生的信息生产成员关系图传递给上层以通知各个节点的工作状态;启下将上层对于隔离某一设备予以具体实施。 Messaging Layer 集群信息层软件: heartbeat (v1, v2) 、heartbeat V3 (可以拆分为:heartbeat, pacemaker, cluster-glue) , corosync 从OpenAIS分离的项目、cman 、keepalived (一般用于两个节点的集群)、ultramokeyCRM(Cluster Resource Manager)
群资源管理器层,它主要是用来提供那些不具有高可用的服务提供高可用性的。它需要借助Messaging Layer来实现工作,因此工作在Messaging Layer上层。资源管理器的主要工作是收集messaging Layer传递的节点信息,并负责信息的计算和比较,并做出相应的动作,如服务的启动、停止和资源转移、资源的定义和资源分配;在每一个节点上都包含一个CRM,且每个CRM都维护这一个CIB(Cluster Information Base,集群信息库),只有在主节点上的CIB是可以修改的,其他节点上的CIB都是从主节点那里复制而来的。CRM会推选出一个用于计算和比较的节点,叫DC(Designated coordinator)指定协调节点,计算由PE(Policy Engine)策略引擎实现,计算出结果后的动作控制由TE(Transition Engine)事务引擎实现;在每个节点上都有一个LRM(local resource manager)本地资源管理器,是CRM的一个子功能,接收TE传递过来的事务,在节点上采取相应动作,如运行RA脚本等。CRM集群资源管理器软件:Haresource (文本配置接口被heartbeat v1 v2包含) 、heartbeat v2包含可以使用crmsh或者heartbeat-gui来进行配置、pacemaker(heartbeat v3分离出来的项目,配置接口:CLI:crm、pcs和GUI:hawk(WEB-GUI)、LCMC、pacemaker-mgmt、pcs)、rgmanager(Cman包含,使用rgmanager(resource group manager)实现管理, 具有Failover Domain故障转移域这一特性,也可以使用RHCS(Redhat Cluster Suite)套件来进行管理:Conga的全生命周期接口,Conga(luci/ricci)先安装后,可用其安装高可用软件,再进行配置。)RA(Resource Rgent)
资源代理层,简单的说就是能够集群资源进行管理的脚本,如启动start,停止stop、重启restart和查询状态信息status等操作的脚本。LRM本地资源管理器负责运行。
资源代理分为:
1、Legacy heartbeat(heatbeat v1版本的资源管理); 2、LSB(Linux Standard Base),主要是/etc/init.d/*目录下的脚,start/stop/restart/status; 3、OCF(Open Cluster Famework),比LSB更专业,更加通用,除了上面的四种操作,还包含monitor、validate-all等集群操作OCF 的规范在http://www.opencf.org/cgi-bin/viewcvs.cgi/specs/ra/resource-agent-api.txt?rev=HEAD。 4、STONITH:实现节点隔离
4)高可用集群架共享存储 高可用集群多节点都需要访问数据,如果各节点访问同一个数据文件都是在同一个存储空间内的,就是说数据共享的就一份,而这个存储空间就共享存储。如Web或mysql高可用集群,他们的数据一般需要放在共享存储中,主节点能访问,从节点也能访问(如前面高可用文章中提到的rsync和DRBD来同步分别存储在主/从节点上的块数据)
共享存储的类型:
DAS(Direct attached storage,直接附加存储):存储设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有数据传输有延时;常用的存储设备:RAID 阵列、SCSI 阵列。 这是设备块级别驱动上实现的共享,持有锁是在节点主机本地上的,无法通知其他节点,所以如果多节点活动模型的集群同时写入数据,会发生严重的数据崩溃错误问题,主备双节点模型的集群在分裂的时候了会出现问题;NAS(network attached storage,网络附加存储):文件级别交互的共享,各存储设备通过文件系统向集群各节点提供共享存储服务,是用C/S框架协议来实现通信的应用层服务。 常用的文件系统:NFS、FTP、CIFS等,如使用NFS实现的共享存储,各节点是通过NFS协议来向共享存储请求文件的。SAN(storage area network、存储区域网络) 块级别的将通信传输网络模拟成SCSI(Small Computer System Interface)总线来使用,节点主机(initiator)和SAN主机(target)都需要SCSI驱动,并借助网络隧道来传输SAN报文,所以接入到SAN主机的存储设备不一定需要是SCSI类型的。常用的SAN:FC光网络(交换机的光接口超贵,代价太高)、IPSAN(iscsi、存取快,块级别,廉价)。
# heartbeat v2+haresource(或crm) (说明:一般常用于CentOS 5.X) # heartbeat v3+pacemaker (说明:一般常用于CentOS 6.X) # corosync+pacemaker (说明:现在最常用的组合) # cman + rgmanager (说明:红帽集群套件中的组件,还包括gfs2,clvm) # keepalived+lvs (说明:常用于lvs的高可用)
0x02 Keepalived 介绍与组成
Keepalived是Linux下一个轻量级别的高可用解决方案;
高可用(High Avalilability,HA),其实两种不同的含义:
广义来讲, 是指整个系统的高可用行狭义的来, 讲就是之主机的冗余和接管答:Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。并且通过虚拟路由器冗余协议 Virtual Router Redundancy Protocol 简称vrrp协议基础之上来实现的,它目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行;
一方面具有服务器状态检测和故障隔离功能另一方面也有 HA cluster功能Keepalived 安全认证有简单字符认证,预共享密钥MD5;
术语解释:
虚拟路由器:Virtual Router 由一个Master路由器和多个Backup路由器组成。通俗讲就是一个路由器集群。虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器物理路由器,如果多个路由器有相同的VRID,那么这些路由器就组成了一个虚拟路由器。master:主设备,虚拟路由器中真正承担报文转发的节点。backup:备用设备,虚拟路由器中某一时刻除Master路由器的其他都有节点。priority:优先级,VRRP根据每个节点的优先级确定节点在虚拟路由器中的地位。如果优先级相同则根据节点的IP地址大小进行比较。VIP:Virtual IPV:虚拟路由器的IP,VIP是用于客户接入的IP地址。MAC:Virutal MAC:虚拟路由器拥有的MAC地址(00-00-5e-00-01-VRID)抢占方式和非抢占方式:抢占方式中只要优先级最高才会成为Master路由器非抢占方式中只要Master路由器没有出现故障,则Baskup路由器的优先级再高也不会成为Master路由器。答:Keepalived主要是通过虚拟路由冗余(VRRP)来实现高可用功能,虽然它没有HeartBeat功能强大,但是Keepalived部署和使用非常的简单,所有配置只需要一个配置文件即可以完成,
安全认证:
简单字符认证、HMAC机制,只对信息做认证 MD5(leepalived不支持)
1) VRRP协议 在现实的网络环境中主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题引入了VRRP协议。 它是一种主备模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信;
其中涉及到两个概念:
物理路由器虚拟路由器VRRP虚拟路由冗余,可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,并且每个虚拟路由器都有一个唯一的标识号称为VRID,一个VRID与一组IP地址构成一个虚拟路由器;这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务;
物理路由设备成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等; 而且其它的物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为“BACKUP的角色”,当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
在VRRP协议中所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
2) 工作原理 Keepalived作为一个高性能集群软件,它还能实现对集群中服务器运行状态的监控以及故障隔离,工作方式有抢占式和非抢占; Keepalived工作在TCP/IP 参考模型的 三层、四层、五层分别为:网络层,传输层和应用层,根据TCP、IP参数模型隔层所能实现的功能:
网络层:运行4个重要协议,互联网络IP协议,互联网络可控制报文协议ICMP、地址转换协议ARP、反向地址转换协议RARP;传输层:提供两个主要的协议,传输控制协议TCP和用户数据协议UDP,传输控制协议TCP可以提供可靠的数据输出服务、IP地址和端口,代表TCP的一个连接端,要获得TCP服务,需要在发送机的一个端口和接收机的一个端口上建立连接,而Keepalived在传输层里利用了TCP协议的端口连接和扫描技术来判断集群节点的端口是否正常,比如对于常见的WEB服务器80端口。Keepalived一旦在传输层探测到这些端口号没有数据响应和数据返回,就认为这些端口发生异常,然后强制将这些端口所对应的节点从服务器集群中剔除掉。在应用层:可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议,Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived工作方式,例如:可以通过编写程序或者脚本来运行Keepalived,而Keepalived将根据用户的设定参数检测各种程序或者服务是否允许正常,如果Keepalived的检测结果和用户设定的不一致时,Keepalived将把对应的服务器从服务器集群中剔除;工作模式:
主/备:单虚拟路径器; 主/主:主/备(虚拟路径器),备/主(虚拟路径器)
3) 结构体系 Keepalived起初是为LVS设计的高可用ipvs服务,由于Keeplalived可以实现对集群节点的状态检测,而IPVS可以实现负载均衡功能,因此,Keepalived借助于第三方模块IPVS就可以很方便地搭建一套负载均衡系统,在这里有个误区,=由于Keepalived可以和IPVS一起很好的工作,很多学员都以为Keepalived就是一个负载均衡软件这种理解是错误,
从下面的图可以看出用户空间层,是建立在内核空间层之上:
用户空间层主要有4个部分:Scheduler I/O Multiplexer 是一个I/O复用分发调度器,它负载安排Keepalived所有内部的任务请求,Memory Mngt 是一个内存管理机制,这个框架提供了访问内存的一些通用方法 Control Plane 是keepalived的控制版面,可以实现对配置文件编译和解析Core componets 这部分主要保护呢了5个部分WatchDog:负载监控checkers和VRRP进程的状况VRRP Stack:负载负载均衡器之间的失败切换FailOver,如果只用一个负载均稀器,则VRRP不是必须的。Checkers:负责真实服务器的健康检查healthchecking,是keepalived最主要的功能。换言之,可以没有VRRP Stack,但健康检查healthchecking是一定要有的。IPVS wrapper:用户发送设定的规则到内核ipvs代码Netlink Reflector:用来设定vrrp的vip地址等。内核空间,主要有两个部分:IPVS 实现复制均衡 NetLINK 模块主要用于实现一些高级路由框架和一些相关参数的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求。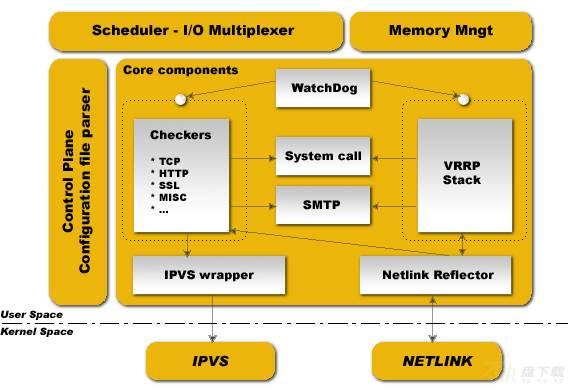
WeiyiGeek.结构体系
keepalived启动后会有三个进程 父进程:内存管理,子进程管理等等 子进程:VRRP子进程 子进程:healthchecker子进程 有图可知,两个子进程都被系统WatchDog看管,两个子进程各自复杂自己的事,healthchecker子进程复杂检查各自服务器的健康程度,例如HTTP,LVS等等,如果healthchecker子进程检查到MASTER上服务不可用了,就会通知本机上的兄弟VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态
0x03 Keepalived 环境与实例
项目需求:利用Keepalived实现httpd的高可用(主/备模式)
KeppAlive项目高可用流程:
项目需求分析,IP及VIP资源分配开启keepAlived服务与httpd服务;vrrp协议单播检测完成地址流动,vip地址所在的节点生成ipvs规则(在配置文件中预先定义,这里是默认)并且为ipvs集群的各RS做健康状态检测;启动keepalived后VIP漂移到主节点上,备节点热备(随时准备切换),这里默认是可以抢占即(Master恢复后VIP将漂移回来)基于脚本调用接口通过执行脚本完成脚本中定义的功能,通过VIP访问httpd服务;模拟环境:CentOS Linux release 7.6.1810 (Core) / Keepalived v1.3.5 (03/19,2017)
#环境设置: #关闭防火墙与selinux设置为disabled systemctl stop firewalld systemctl stop iptables #同步两台机器时间 yum install -y ntpdate && ntpdate us.pool.ntp.org #注:没有安装ntpdate的可以yum一下 #配置hostsIP地址别名 10.10.107.222 master 10.10.107.221 slave
IP | 用途 |
|---|---|
10.10.107.222 | Master / httpd |
10.10.107.221 | Slave / httpd |
10.10.107.236 | VIP 漂移 |
实例流程: Step1.两台http服务器的安装
#两台机均安装httpd $ sudo yum install -y httpd #添加首页 #http服务器1设置 echo “10.10.107.222” >/var/www/html/index.html #http服务器2设置 echo “10.10.107.221” >/var/www/html/index.html #启动并设置开机启动httpd $ sudo systemctl start httpd $ sudo systemctl enable httpd

WeiyiGeek.httpd安装成功验证
Step2.两台keepalived主机的设置
#两台机均安装keepalived #安装依赖文件与keepalive $ sudo yum install -y openssl openssl-devel keepalived

WeiyiGeek.keepalived
Step3.keepalived配置文件修改:
vim /etc/keepalived/keepalived.conf
#主节点(我将我修改的罗列出来)
global_defs {
router_id master #路由id,不能重复(采用机器名即可)
}
vrrp_instance VI_1 {
state MASTER ## 初始化设置为MASTER节点
interface ens192 #网卡不对的要进行修改
virtual_router_id 51 # # 同一个VRRP实例中每个节点的虚拟路由ID必须相同
priority 100 # MASTER节点的优先级必须高于BACKUP节点
virtual_ipaddress {
10.10.107.236/24 dev ens192 # 主备节点的VIP一定要相同
}
}
#备 节点
global_defs {
router_id slave #路由id,不能重复
}
vrrp_instance VI_1 {
state BACKUP ## 初始化设置为BACKUP 节点(重要的点)
interface ens192 #网卡不对的要进行修改
virtual_router_id 51 # # 同一个VRRP实例中每个节点的虚拟路由ID必须相同
priority 90 # BACKUP 节点的优先级必须低于于MASTER节点 (重要的点)
virtual_ipaddress {
10.10.107.236/24 dev ens192 # 主备节点的VIP一定要相同
}
}
#主备都相同 虚拟IP服务
global_defs {
#vrrp_strict 为了能更好的测试建议把该项注释(为什么要注释看末尾)
}
virtual_server 10.10.107.236 80 {
delay_loop 6 #设定检查间隔
lb_algo rr # #指定LVS算法
lb_kind NAT # #指定LVS模式
nat_mask 255.255.255.0
persistence_timeout 50
protocol TCP
#后端监控的主机
real_server 10.10.107.222 80 {
weight 1
}
real_server 10.10.107.221 80 {
weight 1
}
} 解释说明:/etc/keepalived/keepalived.conf为keepalived的主配置文件。
以上配置state表示主节点为10.10.107.222,副节点为10.10.107.221。虚拟为IP10.10.107.236。后端的真实服务器为10.10.107.222和10.10.107.221,当通过10.10.107.236访问web服务器时,自动转到后端真实服务器,后端节点的权重相同,类似轮询的模式。Step4.keepalived的启动与测试
systemctl start httpd keepalived #启动服务 systemctl status keepalived httpd #查看运行状态 $ ip addr show ens192 #查看VIP漂移状态

WeiyiGeek.VIP
#在我们windows机器进行测试漂移
http://10.10.107.236/
10.10.107.222 Master
#关闭主Master的keepalive服务(关闭计算机进行测试)
[root@master ~]# service stop keepalived
[root@slave sec]# ip addr show ens192
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:b3:6d:fd brd ff:ff:ff:ff:ff:ff
inet 10.10.107.221/24 brd 10.10.107.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 10.10.107.236/24 scope global secondary ens192
valid_lft forever preferred_lft forever
inet6 fe80::25f6:1911:3d05:2922/64 scope link noprefixroute
valid_lft forever preferred_lft forever
#在我们windows机器进行测试漂移(此时漂移到从机上面)
http://10.10.107.236/
10.10.107.221 Slave
#当主Master机器恢复正常的时候,便会接管回资源
[root@master ~]# service keepalived start
http://10.10.107.236/
10.10.107.222 Master 
WeiyiGeek.漂移案例
0x04 命令详解
参考:https://www.keepalived.org/doc/programs_synopsis.html keepalived命令:
-f,-use-file = FILE
使用指定的配置文件。默认配置文件是“/etc/keepalived/keepalived.conf”。
-P,-vrrp
只运行VRRP子系统。这对于不使用IPVS负载平衡器的配置非常有用。
-C, - 检查
只运行健康检查子系统。这对于使用IPVS负载均衡器和单个导向器而不进行故障切换的配置非常有用。
-l,-log-console
将消息记录到本地控制台。默认行为是将消息记录到系统日志。
-D,-log-detail
详细的日志消息。
-S,-log-facility = [0-7]
将syslog工具设置为LOG_LOCAL [0-7]。默认的系统日志工具是LOG_DAEMON。
-V,-dont-release-vrrp
不要在守护进程中删除VRRP VIP和VROUTE。默认行为是在keepalived退出时删除所有VIP和VROUTE
-I,-dont-release-ipvs
不要在守护进程停止时移除IPVS拓扑。它在keepalived退出时从IPVS虚拟服务器表中删除所有条目的默认行为。
-R,不要重生
不要重新生成子进程。默认行为是在任何进程退出时重新启动VRRP和检查器进程。
-n,-dont-fork
不要分解守护进程。该选项将导致keepalived在前台运行。
-d,-dump-conf
转储配置数据。
-p,-pid = FILE
父指定的进程使用指定的pidfile。 keepalived的默认pid文件是“/var/run/keepalived.pid”。
-r,-vrrp_pid = FILE
为VRRP子进程使用指定的pidfile。 VRRP子进程的默认pid文件是“/var/run/keepalived_vrrp.pid”。
-c,-checkers_pid = FILE
针对检查者子进程使用指定的pidfile。检查器子进程的默认pid文件是“/var/run/keepalived_checkers.pid”。
-x,-snmp
启用SNMP子系统。 genhash实用程序:二进制文件用于生成摘要字符串。
-use-ssl,-S
使用SSL连接到服务器。
-server <host>,-s
指定要连接的IP地址。
-port <port>,-p
指定要连接的端口。
-url <url>,-u
指定要生成散列的文件的路径。
-use-virtualhost <host>,-V
指定要与HTTP标头一起发送的虚拟主机。
-hash <alg>,-H #即生成的是SHA1密文,还是MD5密文
指定散列算法以制作目标页面的摘要。请查看帮助屏幕中的可用列表,并标记默认标记。
-verbose,-v
请输出详细信息。
-help,-h
显示程序帮助屏幕并退出。
-release, -r
显示版本号(版本)并退出。 0x05 配置文件
配置文件:
主配置文件:/etc/keepalived/keepalived.conf 主程序文件:/usr/sbin/keepalived 提供校验码:/usr/bin/genhash Unit File:/usr/lib/systemd/system/keepalived.service Unit File的环境配置文件:/etc/sysconfig/keepalived keepalived的日志默认在:tailf /var/log/messages
#keepalived的配置文件分为三个部分,分别是:
Global Configuration:全局配置部分
Global definition
static routes/address
VRRPD Configuration:VRRPD配置部分
1. vrrp_script : 添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的VRRP Instance记录
2. vrrp_sync_group : VRRP synchronization group:VRRP同步组
3. garp_group : 当检测到组里面任意服务发生变化时候,将进行主从切换
4. vrrp_instance : VRRP instance:VRRP实例配置
LVS Configuration:LVS配置部分
Virtual server: ipvs的RS和VS
#全局定义模块
! Configuration File for keepalived
global_defs {
notification_email {
sysadmin@firewall.net #邮件报警收件人
}
notification_email_from sender@firewall.net #右键报警发信人
smtp_server 192.168.200.1 #连接smtp服务于超时时间
#smtp_helo_name <HOST_NAME>:指定在HELO消息中所使用的名称。默认为本地主机名。
smtp_connect_timeout 30
router_id LVS_DEVEL #此处注意router_id为负载均衡标识,在局域网内应该是唯一的建议使用机器名(不能重复)
#### 组播方式-add ####
vrrp_mcast_group4 224.1.101.33 #设置组播地址,其他主机也一样
vrrp_mcast_group6 ff02::12 #指定发送VRRP组播消息所使用的IPV6组播地址。默认是ff02::12
#default_interface eth0:设置静态地址默认绑定的端口。默认是eth0。
##### end
##### LVS -add ###
lvs_sync_daemon <INTERFACE> <VRRP_INSTANCE> [id <SYNC_ID>] [maxlen <LEN>] [port <PORT>] [ttl <TTL>] [group <IP ADDR>]
设置LVS同步服务的相关内容。可以同步LVS的状态信息。
INTERFACE:指定同步服务绑定的接口。
VRRP_INSTANCE:指定同步服务绑定的VRRP实例。
id <SYNC_ID>:指定同步服务所使用的SYNCID,只有相同的SYNCID才会同步。范围是0-255.
maxlen:指定数据包的最大长度。范围是1-65507
port:指定同步所使用的UDP端口。
group:指定组播IP地址。
lvs_flush:在keepalived启动时,刷新所有已经存在的LVS配置。
##### end
###start
vrrp_version 2|3: #设置默认的VRRP版本。默认是2.
vrrp_check_unicast_src:在单播模式中,开启对VRRP数据包的源地址做检查,源地址必须是单播邻居之一。
###end
vrrp_skip_check_adv_addr #默认是不跳过检查。检查收到的VRRP通告中的所有地址可能会比较耗时,
#设置此命令的意思是,如果通告与接收的上一个通告来自相同的master路由器,则不执行检查(跳过检查)。
vrrp_strict #vrrp通信严格模式(不能ping通) 严格遵守VRRP协议。下
#列情况将会阻止启动Keepalived:1. 没有VIP地址。2. 单播邻居。3. 在VRRP版本2中有IPv6地址。
vrrp_garp_interval 0
vrrp_gna_interval 0
#静态地址和路由配置范例 (在复杂的环境下可能需要配置,一般不会用这个来配置)
# static_ipaddress{
# 192.168.1.1/24 brd + dev eth0 scope global #相当于: ip addr add 192.168.1.1/24 brd + dev eth0 scope global
# 192.168.1.2/24 brd + dev eth1 scope global #就是给eth1配置IP地址
# }
# static_routes{
# src $SRC_IP to $DST_IP dev $SRC_DEVICE #路由和ip同理,一般这个区域不需要配置
# src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
# }
#杂项
vrrp_iptables #不添加任何iptables规则。默认是添加iptables规则的。
#
vrrp_priority <-20 -- 19> #:设置VRRP进程的优先级。
checker_priority <-20 -- 19> #:设置checker进程的优先级。
vrrp_no_swap #:vrrp进程不能够被交换。
checker_no_swap #:checker进程不能够被交换。
script_user <username> [groupname] #设置运行脚本默认用户和组,默认用户为keepalived_script(需要该用户存在),否则为root用户。默认groupname同username。
enable_script_security #如果脚本路径的任一部分对于非root用户来说,都具有可写权限,则不会以root身份运行脚本。
nopreempt #默认是抢占模式 要是用非抢占式的就加上nopreempt
}
#VRRP同步组(synchroization group)配置范例
vrrp_sync_group VG_1 {
group {
http #实例名
mysql #实例名
}
notify_master /path/to/to_master.sh #表示当切换到master状态时,要执行的脚本
notify_backup /path_to/to_backup.sh #表示当切换到backup状态时,要执行的脚本
notify_fault "/path/fault.sh VG_1"
notify /path/to/notify.sh
smtp_alert #表示切换时给global defs中定义的邮件地址发送右键通知 (当状态发生改变时,发送邮件)
}
# VRRP脚本定义块 (主主、主备配置)
#首先在vrrp_script区域定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
#然后在实例(vrrp_instance)里面引用,有点类似脚本里面的函数引用一样:先定义,后引用函数名
vrrp_script check_running {
script "/usr/local/bin/check_running" #指定要执行的脚本的路径。
interval 10 #脚本执行间隔
weight 10 #脚本结果导致的优先级变更:10表示优先级+10;-10则表示优先级-10 #调整优先级。默认为2.
rise <INTEGER> #:执行成功多少次才认为是成功。
fall <INTEGER> #:执行失败多少次才认为失败。
user <USERNAME> [GROUPNAME] #:运行脚本的用户和组。
init_fail #:假设脚本初始状态是失败状态。
}
#VRRP实例定义块 (主主配置) 定义vrrp实例名
vrrp_instance VI_1 {
state MASTER #状态只有MASTER和BACKUP两种,并且要大写,MASTER为工作状态,BACKUP是备用状态。
interface ens192 #指定网卡接口
use_vmac [<VMAC_INTERFACE>] #在指定的接口产生一个子接口,如vrrp.51,该接口的MAC地址为组播地址,通过该接口向外发送和接收VRRP包。
vmac_xmit_base #通过基本接口向外发送和接收VRRP数据包,而不是通过VMAC接口。
native_ipv6 #强制VRRP实例使用IPV6.(当同时配置了IPV4和IPV6的时候)
#dont_track_primary 忽略VRRP的interface错误
# track_interface {
# eth0
# eth1
# }
#踪接口,设置额外的监控,里面任意一块网卡出现问题,都会进入故障(FAULT)状态,例如,用nginx做均衡器的时候,内网必须正常工作,如果内网出问题了,这个均衡器也就无法运作了,所以必须对内外网同时做健康检查
#mcast_src_ip <IPADDR> #设置多播地址224.0.0.17(这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口),
#指定发送组播数据包的源IP地址。默认是绑定VRRP实例的接口的主IP地址。
#unicast_src_ip <IPADDR>:指定发送单薄数据包的源IP地址。默认是绑定VRRP实例的接口的主IP地址。
#garp_master_delay 10 #在切换到master状态后,延迟进行免费的ARP(gratuitous ARP)请求
lvs_sync_daemon_inteface eth1 #默认没有相当于心跳线接口,DR模式用的和上面的接口一样,也可以用机器上的其他网卡eth1,用来防止脑裂。
virtual_router_id 51 # #同一组的vrrp成员,该id需要一致
priority 100 #优先级,范围(0-255) 且 主 > 备
advert_int 1 #发送hello的时间间隔(检查间隔,)
#通过密码身份验证
authentication {
auth_type PASS #PASS简单密码认证(推荐),AH:IPSEC认证(不推荐)。
auth_pass 11111111 #密码为8位,不能用默认的密码
}
virtual_ipaddress {
#定义虚拟IP(VIP),但ip默认32位子网掩码
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
10.10.107.236/24 dev ens192 label eth192
10.10.107.237
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
#不抢占(只针对BACKUP机器生效)
nopreempt #设置为不抢占。默认是抢占的,当高优先级的机器恢复后,会抢占低优先级的机器成为MASTER,
#而不抢占,则允许低优先级的机器继续成为MASTER,即使高优先级的机器已经上线。
preemtp_delay 300 #抢占延迟
debug #debug级别
notify master #和sync group这里设置的含义一样,可以单独设置
#调用vrrp_script中的脚本执行
track_script {
<SCRIPT_NAME> weight <-254-254>
check_running weight 20
}
}
vrrp_instance VI_2{ #定义一个虚拟路由器,第二个
state BACKUP #当前状态,从的
interface ens193 #当前的vrp应用,绑定到那个网卡设备上
virtual_router_id 34 #这个虚拟ip,与其他主机要保持一至
priority 96 #优先级,低于master主机
advert_int 1
authentication {
auth_type PASS #密码认证
auth_pass a6b7c8d9 #密码为8位,不能用默认的密码,这里修改一下
}
virtual_ipaddress {#虚拟ip地址
172.16.15.99/16 dev eth0
}
}
#LVS 配置:
#这里LVS配置并不是指真的安装LVS然后用ipvsadm来配置他,而是用keepalived的配置文件来代替ipvsadm来配置LVS
# virtual server可以以下面三种的任意一种来配置
1. virtual server IP port
2. virtual server fwmark int
3. virtual server group string
#示例1.
virtual_server 10.10.107.236 80 { #设置一个virtual server: VIP:Vport
delay_loop 6 ## service polling的delay时间,即服务轮询的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #LVS调度算法
lb_kind NAT|DR|TUN #集群模式
persistence_timeout 50 # #会话保持时间(秒为单位),即以用户在50秒内被分配到同一个后端realserver
#persistence_granularity <NETMASK> #LVS会话保持粒度,ipvsadm中的-M参数,默认是0xffffffff,即每个客户端都做会话保持
protocol TCP|UDP|SCTP #健康检查用的是TCP还是UDP,4层协议。
# virtualhost <string> #HTTP_GET做健康检查时,检查的web服务器的虚拟主机(即host:头)
# sorry_server <IPADDR> <PORT> #备用机,就是当所有后端realserver节点都不可用时,就用这里设置的,也就是临时把所有的请求都发送到这里啦
#后端真实节点主机的权重等设置,主要后端有几台这里就要设置几个
real_server 10.10.107.221 80 {
weight 1 #默认为2
inhibit_on_failure #表示在节点失败后,把他权重设置成0,而不是冲IPVS中删除
notify_up <STRING> | <QUOTED-STRING> #检查服务器正常(UP)后,要执行的脚本
notify_down <STRING> | <QUOTED-STRING> #检查服务器失败(down)后,要执行的脚本
#下面是常用的健康检查方式,健康检查方式一共有【HTTP_GET|SSL_GET】|TCP_CHECK|SMTP_CHECK|MISC_CHECK这些
HTTP_GET|SSL_GET { # #健康检查方式
url { # #要坚持的URL,可以有多个
path /testurl/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d # 摘要。计算方式 genhash -s 10.10.107.221 -p 80 -u /index.html
# MD5SUM = 09174a47a3944b5604699f5cb48e4e3e
status_code 200 #返回状态码
}
connect_ip <IP ADDRESS> #:连接的IP地址。默认是real server的ip地址。
connect_port <PORT> #:连接的端口。默认是real server的端口。
bindto <IP ADDRESS> #:发起连接的接口的地址。
bind_port <PORT> #:发起连接的源端口。
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 2 #重连间隔
fwmark <INTEGER> #使用fwmark对所有出去的检查数据包进行标记。
warmup <INT> #指定一个随机延迟,最大为N秒。可防止网络阻塞。如果为0,则关闭该功能。
}
}
#检测mysql端口是否可以连接
real_server 10.10.107.33 3306 {
weight 1
TCP_CHECK {
# connect_port 3306
# bindto 10.10.107.33 #本地服务地址(即连接到数据库机器)
connect_timeout 3 #连接超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试间隔时间
}
}
# SMTP方式,这个可以用来给邮件服务器做集群
SMTP_CHECK
host {
connect_ip <IP ADDRESS>
connect_port <PORT> #默认检查25端口
14 KEEPALIVED
bindto <IP ADDRESS>
}
connect_timeout <INTEGER>
retry <INTEGER>
delay_before_retry <INTEGER>
# "smtp HELO"?|·-?ê§?à"
helo_name <STRING>|<QUOTED-STRING>
} #SMTP_CHECK
#MISC方式,这个可以用来检查很多服务器只需要自己会些脚本即可
MISC_CHECK
{
misc_path <STRING>|<QUOTED-STRING> #外部程序或脚本
misc_timeout <INT> #脚本或程序执行超时时间
misc_dynamic #这个就很好用了,可以非常精确的来调整权重,是后端每天服务器的压力都能均衡调配,这个主要是通过执行的程序或脚本返回的状态代码来动态调整weight值,使权重根据真实的后端压力来适当调整,不过这需要有过硬的脚本功夫才行哦
#返回0:健康检查没问题,不修改权重
#返回1:健康检查失败,权重设置为0
#返回2-255:健康检查没问题,但是权重却要根据返回代码修改为返回码-2,例如如果程序或脚本执行后返回的代码为200,#那么权重这回被修改为 200-2
}
#DNS检测
DNS_CHECK {
connect_ip <IP ADDRESS>:连接的IP地址。默认是real server的ip地址。
connect_port <PORT>:连接的端口。默认是real server的端口。 默认是25端口
bindto <IP ADDRESS>:发起连接的接口的地址。
bind_port <PORT>:发起连接的源端口。
connect_timeout <INT>:连接超时时间。默认是5s。
fwmark <INTEGER>:使用fwmark对所有出去的检查数据包进行标记。
warmup <INT>:指定一个随机延迟,最大为N秒。可防止网络阻塞。如果为0,则关闭该功能。
retry <INT>:重试次数。默认是3次。
type <STRING>:DNS query type。A/NS/CNAME/SOA/MX/TXT/AAAA
name <STRING>:DNS查询的域名。默认是(.)
}
} 总结:
VRRP脚本(vrrp_script)和VRRP实例(vrrp_instance)属于同一个级别VRRP脚本中的weight权重:如果脚本执行成功(退出状态码为0),weight大于0,则priority增加。如果脚本执行失败(退出状态码为非0),weight小于0,则priority减少。其他情况下,priority不变。脚本文件要加上x权限同时指令最好写绝对路径。0x06 入坑记
原因:防火墙/keepalived配置文件中启动了vrrp_strict 解决办法:
关闭防火墙 注释:keepalived.conf配置中 #vrrp_strict 参数 [root@slave sec]# ping 10.10.107.236 PING 10.10.107.236 (10.10.107.236) 56(84) bytes of data. 64 bytes from 10.10.107.236: icmp_seq=1 ttl=64 time=0.056 ms
我们可以通过tcpdump来抓取vrrp通信包进行查看;
tcpdump -i ens192 vrrp -vv -c 2
tcpdump: listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
11:21:31.013073 IP (tos 0xc0, ttl 255, id 64656, offset 0, flags [none], proto VRRP (112), length 40)
10.10.107.254 > vrrp.mcast.net: vrrp 10.10.107.254 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 5, prio 120, authtype none, intvl 1s, length 20, addrs: gateway
11:21:31.357117 IP (tos 0xc0, ttl 255, id 223, offset 0, flags [none], proto VRRP (112), length 40)
master > vrrp.mcast.net: vrrp master > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20, addrs: master auth "11111111" 先清理master的arp,将vip切回至master,ping vip正常再清理slave的arp
#组合命令清楚所有arp缓存:
arp -n | awk '/^[1-9]/{system("arp -d "$1)}' 答:tcpdump -i eth0 -nn host 224.1.101.33 #对多播地址抓包
haproxy的故障转移
[root@localhost ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id teacher
}
vrrp_script chk_haproxy {
script "lsof -i:80 | grep haproxy || exit 1"
interval 2
fail 1
}
vrrp_instance lvs_inst {
state MASTER
interface ens33
virtual_router_id 51
priority 250
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
10.18.42.124
}
} 主从节点都必须有的检测haproxy服务状态的文件(注:该文件必须有可执行权限!!!): vim /opt/check_haproxy.sh
#!/bin/bash
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then###判断haproxy是否已经启动
systemctl start haproxy###如果没有启动,则启动haproxy程序
fi
sleep 2###睡眠两秒钟,等待haproxy完全启动
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then###判断haproxy是否已经启动
systemctl stop keepalived###如果haproxy没有启动起来,则将keepalived停掉,则VIP
自动漂移到另外一台haproxy机器,实现了对haproxy的高可用
fi mysql 与 keepalived
https://blog.51cto.com/gaowenlong/1888036 实现MySQL的故障转移
1)、实现master与slave1两台主机的复制(AA复制) 2)、利用keepalived 的健康检查功能,检测本机的3306端口是否存活,如果端口失效,则自动执行自定义脚本 3)、自定义脚本的内容为:kill 本机的keepalived进程,并删除本机VIP;当本机keepalived进程被kill掉之后,另一台主机的keepalived进程即可获得虚拟IP,实现的故障转移 4)、测试:客户端连接keepalived提供的虚拟IP(mysql需要事先授权grant连接)
[root@localhost ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id teacher
}
vrrp_instance lvs_inst {
state MASTER
interface ens33
virtual_router_id 51
priority 250
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.18.42.123
}
}
virtual_server 10.18.42.123 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
#persistence_timeout 50
protocol TCP
real_server 10.18.42.251 3306 {
weight 1
notify_down /etc/keepalived/kill.sh #检测失败执行的脚本
TCP_CHECK {
connect_port 3306
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
[root@localhost ~]# cat /etc/keepalived/kill.sh
#!/bin/bash
pkill keepalived
#systemctl stop keepalived #尽量使用此方式关闭keepalived
ip addr del dev ens33 10.18.42.123/32 加载全部内容