3.10内核 vs 5.4内核——内存不足场景pk
作者:快盘下载 人气:由于早期的云服务器,大量存量3.10内核作为cvm的操作系统内核。3.10内核存在着很多已知问题,其中的常客之一便是内存不足场景下,内存回收引发的问题。 内存回收和OOM一直是Linux中一个饱受诟病的问题,其路径内核一直在优化,所以从理论上新版本内核一定是优于老版本。 本文通过构造用例测试,来针对3.10和5.4内核在内存不足场景下的表现进行分析对比,以说明5.4会在内存不足的场景下有更好的表现。
结论
【一句话结论】
5.4相比3.10内存不足时,直接回收的耗时更短,因此更易进入oom逻辑,从而杀掉进程来释放内存;而3.10则会存在hung死、回收慢导致内存释放慢等问题;因此5.4在内存不足的场景下表现要远优于3.10。
【测试数据】
使用两台IT5 64C 256G 100M的cvm,一台3.10 内部内核,一台TencentOS 5.4.119-19-0009,内存相关内核参数相同。
构造测试程序每秒生成一个进程分配10G内存,分配完while 1不释放,当内存不足1G时,每秒分配10M内存,持续不断分配内存直到被系统oom杀掉。
在只跑测试程序的情况下,进入oom逻辑的时间分别为:
3.10 30-31s
5.4 29-30s
在打入高流量(只收包)的情况下,进入oom逻辑的时间分别为:
3.10 37-38s
5.4 27-28s
在打入高流量(同时收发包)的情况下,进入oom逻辑的时间分别为:
3.10 35s;且测试五次会有一hung死,不会进入oom
5.4 30-31s
详情请见“trace数据分析”章节。
分析
整个问题的分析过程,vmcore分析相对冗余,属于又臭又长,不感兴趣的同学建议直接关注“trace数据分析”中的第2-4小节的数据“3.10-5.4内存回收路径代码举例对比分析”中的代码对比分析。
vmcore前瞻分析
从业务反馈的一个hung死case分析开始。
这个case并没能分析出问题的详细逻辑,只是观察了问题时间机器内存里的种种“迹象”,并做出了一些对应的推论。
开始分析,先看到机器hung死时的串口日志,是在网络栈上的内存分配:

对于3.10因为内存回收hung死的机器,一般会通过sysrq魔术键触发crash来生成dump文件,进行进一步的分析。
拿到dump文件后,进入crash进行分析。
查看内存基本情况,内存耗尽,cache不高:
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 65821943 251.1 GB ----
FREE 135924 531 MB 0% of TOTAL MEM
USED 65686019 250.6 GB 99% of TOTAL MEM
SHARED 10711 41.8 MB 0% of TOTAL MEM
BUFFERS 831 3.2 MB 0% of TOTAL MEM
CACHED 5255 20.5 MB 0% of TOTAL MEM
SLAB 89428 349.3 MB 0% of TOTAL MEM
TOTAL HUGE 0 0 ----
HUGE FREE 0 0 0% of TOTAL HUGE
TOTAL SWAP 0 0 ----
SWAP USED 0 0 0% of TOTAL SWAP
SWAP FREE 0 0 0% of TOTAL SWAP
COMMIT LIMIT 32910971 125.5 GB ----
COMMITTED 71816972 274 GB 218% of TOTAL LIMIT
crash> p min_free_kbytes
min_free_kbytes = $1 = 64900查看hung死进程:
crash> ps -l | grep UN | tail
[2856682881102] [UN] PID: 9876 TASK: ffff883f39544d70 CPU: 47 COMMAND: "sap1007"
[2856682877615] [UN] PID: 8579 TASK: ffff883f5d31b3a0 CPU: 27 COMMAND: "m3dbnode"
[2856682861078] [UN] PID: 1320 TASK: ffff881f8ea10000 CPU: 59 COMMAND: "nscd"
[2856682846246] [UN] PID: 8657 TASK: ffff881f816499d0 CPU: 61 COMMAND: "m3dbnode"
[2856682836259] [UN] PID: 8804 TASK: ffff883f5effcd70 CPU: 34 COMMAND: "m3dbnode"
[2856682831462] [UN] PID: 8945 TASK: ffff883f445633a0 CPU: 37 COMMAND: "m3dbnode"
[2856682820876] [UN] PID: 1859 TASK: ffff881f816899d0 CPU: 56 COMMAND: "crond"
[2856682815523] [UN] PID: 3913 TASK: ffff881f817b8000 CPU: 49 COMMAND: "agentWorker"
[2856682800170] [UN] PID: 1844 TASK: ffff881f8c1d0000 CPU: 32 COMMAND: "in:imjournal"
[2753630505936] [UN] PID: 266 TASK: ffff883f62614d70 CPU: 51 COMMAND: "kworker/51:0"hung住最久的kworker是因为在等kthreadd创建内核线程:
crash> bt ffff883f62614d70
PID: 266 TASK: ffff883f62614d70 CPU: 51 COMMAND: "kworker/51:0"
#0 [ffff883f62623bb0] __schedule at ffffffff819fcb9e
#1 [ffff883f62623c18] schedule at ffffffff819fd0e9
#2 [ffff883f62623c28] schedule_timeout at ffffffff819fb629
#3 [ffff883f62623cb8] wait_for_completion at ffffffff819fd597
#4 [ffff883f62623d18] kthread_create_on_node at ffffffff810734d3
#5 [ffff883f62623dd0] create_worker at ffffffff8106c824
#6 [ffff883f62623e20] manage_workers at ffffffff8106ca8d
#7 [ffff883f62623e68] worker_thread at ffffffff8106cfa3
#8 [ffff883f62623ec8] kthread at ffffffff8107366f
#9 [ffff883f62623f50] ret_from_fork at ffffffff81ad7d48
crash> task -R sched_info ffff883f62614d70
PID: 266 TASK: ffff883f62614d70 CPU: 51 COMMAND: "kworker/51:0"
sched_info = {
pcount = 24,
run_delay = 15283,
last_arrival = 2753630505936,
last_queued = 0
},
crash> log | grep sysrq
[ 2856.304036] IP: [<ffffffff813c5196>] sysrq_handle_crash+0x16/0x20
[ 2856.304036] RIP: 0010:[<ffffffff813c5196>] [<ffffffff813c5196>] sysrq_handle_crash+0x16/0x20
[ 2856.304036] [<ffffffff813c5952>] __handle_sysrq+0xa2/0x170
[ 2856.304036] [<ffffffff813c5da5>] sysrq_filter+0x335/0x420
[ 2856.304036] RIP [<ffffffff813c5196>] sysrq_handle_crash+0x16/0x20
crash> pd 2856-2753
$2 = 103kthreadd回收内存上等spinlock:
crash> bt 2
PID: 2 TASK: ffff881f931599d0 CPU: 24 COMMAND: "kthreadd"
#0 [ffff881fbfd05e70] crash_nmi_callback at ffffffff810294d2
#1 [ffff881fbfd05e80] nmi_handle at ffffffff81a00869
#2 [ffff881fbfd05ec8] do_nmi at ffffffff81a00980
#3 [ffff881fbfd05ef0] end_repeat_nmi at ffffffff819ffe91
[exception RIP: _raw_spin_lock+26]
RIP: ffffffff819ff3ca RSP: ffff881f93187a20 RFLAGS: 00000246
RAX: 0000000000000001 RBX: ffff883f62168000 RCX: 0000000000000000
RDX: 0000000000000001 RSI: ffff881f93187bb0 RDI: ffffffff823c4120
RBP: ffff881f93187a20 R8: 0000000000000000 R9: 0000000000000040
R10: 0000000000000000 R11: 0000000000000000 R12: ffff883f62168000
R13: 0000000000000000 R14: ffff881f93187bb0 R15: ffff883f621683b0
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
--- <NMI exception stack> ---
#4 [ffff881f93187a20] _raw_spin_lock at ffffffff819ff3ca
#5 [ffff881f93187a28] put_super at ffffffff8118e9e9
#6 [ffff881f93187a40] prune_super at ffffffff8118fbae
#7 [ffff881f93187a78] shrink_slab at ffffffff81134de1
#8 [ffff881f93187b18] do_try_to_free_pages at ffffffff811381dd
#9 [ffff881f93187ba0] try_to_free_pages at ffffffff81138405
#10 [ffff881f93187c48] __alloc_pages_nodemask at ffffffff8112d654
#11 [ffff881f93187d80] copy_process at ffffffff81049204
#12 [ffff881f93187e08] do_fork at ffffffff8104a7f0
#13 [ffff881f93187e78] kernel_thread at ffffffff8104ab56
#14 [ffff881f93187e88] kthreadd at ffffffff81074125
#15 [ffff881f93187f50] ret_from_fork at ffffffff81ad7d48 这里这个spinlock是一个全局锁sb_lock(省略找参数过程)。
从上面的堆栈,结合代码,知道内存分配的代码路径是:
alloc_pages_nodemask->alloc_pages_slowpath->__alloc_pages_direct_reclaim
direct_reclaim只有退出,才会进入oom逻辑。
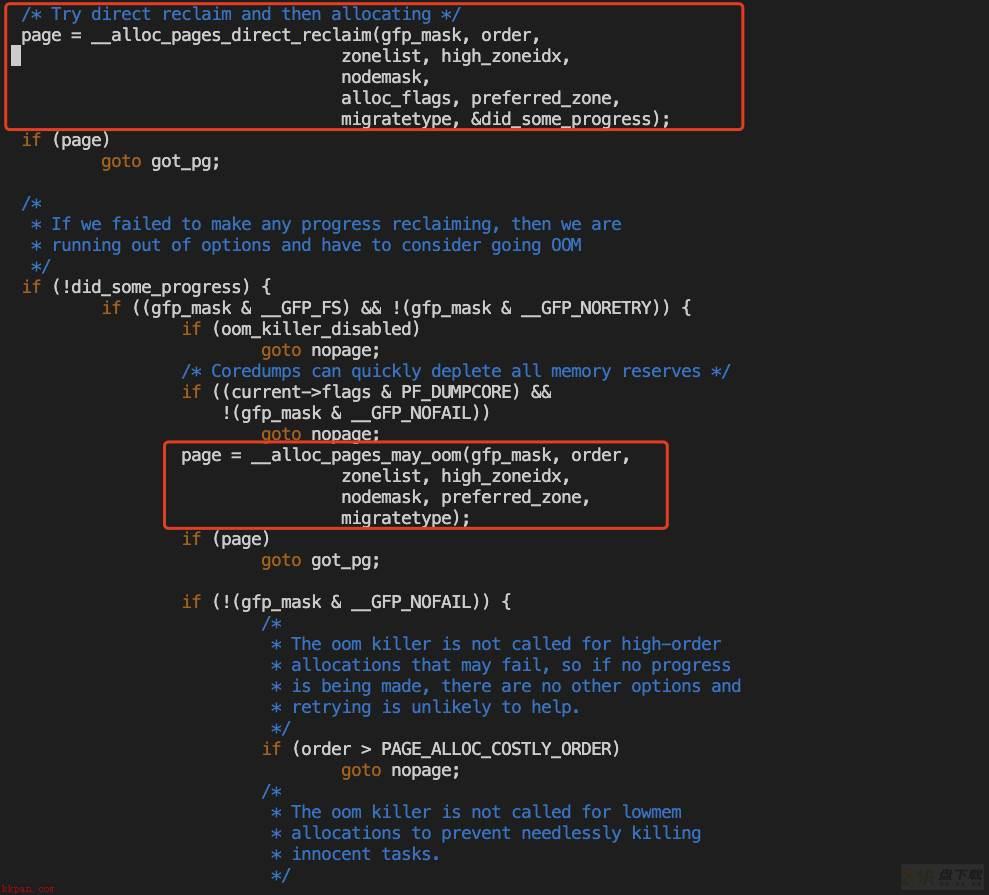
而kthreadd是卡在了direct_reclaim环节的shrink_slab(direct_reclaim除了回收cache,主要的一个动作就是回收slab,而从前面的内存总体情况里可以看到,cache不多)里。
看下汇编确认调用逻辑无误:
crash> dis -r ffffffff8112d654 | tail
0xffffffff8112d63f <__alloc_pages_nodemask+1711>: mov %r14,%rcx
0xffffffff8112d642 <__alloc_pages_nodemask+1714>: mov %r13d,%edx
0xffffffff8112d645 <__alloc_pages_nodemask+1717>: mov %r12,%rdi
0xffffffff8112d648 <__alloc_pages_nodemask+1720>: mov %rax,0x828(%r15)
0xffffffff8112d64f <__alloc_pages_nodemask+1727>: callq 0xffffffff81138300 <try_to_free_pages>
0xffffffff8112d654 <__alloc_pages_nodemask+1732>: andl $0xfffff7ff,0x14(%r15)确认是从direct recliam进去的:
crash> dis -r ffffffff811381dd | tail
0xffffffff811381c5 <do_try_to_free_pages+1045>: mov -0x48(%rbp),%rax
0xffffffff811381c9 <do_try_to_free_pages+1049>: test %rax,%rax
0xffffffff811381cc <do_try_to_free_pages+1052>: jne 0xffffffff81138178 <do_try_to_free_pages+968>
0xffffffff811381ce <do_try_to_free_pages+1054>: mov (%r15),%rsi
0xffffffff811381d1 <do_try_to_free_pages+1057>: mov -0x70(%rbp),%rdi
0xffffffff811381d5 <do_try_to_free_pages+1061>: mov %r13,%rdx
0xffffffff811381d8 <do_try_to_free_pages+1064>: callq 0xffffffff81134d30 <shrink_slab>
0xffffffff811381dd <do_try_to_free_pages+1069>: mov -0x68(%rbp),%rdx
crash> dis -r ffffffff81134de1 | tail
0xffffffff81134dd1 <shrink_slab+161>: mov %r13,%rsi
0xffffffff81134dd4 <shrink_slab+164>: mov %r15,%rdi
0xffffffff81134dd7 <shrink_slab+167>: test %rbx,%rbx
0xffffffff81134dda <shrink_slab+170>: cmove %rax,%rbx
0xffffffff81134dde <shrink_slab+174>: callq *(%r15)
0xffffffff81134de1 <shrink_slab+177>: movslq %eax,%r14在shrink_slab里,内核会去遍历注册的shrinker,一一调用来回收slab。
注册的shrinker绝大多数是文件系统的,用于回收对应文件系统的元数据(drop 3干的事)。

查看有多少shrinker:
crash> list -H shrinker_list shrinker.list | wc -l
42
crash> p shrinker_rwsem
shrinker_rwsem = $1 = {
count = 50,
wait_lock = {
raw_lock = {
lock = 0 '�00',
spinners = 0 '�00'
}
},
wait_list = {
next = 0xffffffff81f9b870 <shrinker_rwsem+16>,
prev = 0xffffffff81f9b870 <shrinker_rwsem+16>
}
}查看shrinker里有多少是文件系统的接口prune_super:
crash> list -H shrinker_list shrinker.list -s shrinker.shrink | grep prune_super | wc -l
37
crash> mount | wc -l
31这里省略从内核栈里找shrinker参数过程,shrinker 地址为ffff883f621683b0。
查看遍历到第几个shrinker:
crash> list -H shrinker_list shrinker.list |awk '{print NR":"$0}' | grep ffff883f621683b0
6:ffff883f621683b0遍历到第六个shrinker。
查看到68个进程在direct_reclaim路径上,也就是说这里这把sb_lock锁至少要过68*37次。
# cat foreach_bt.txt | grep shrink_slab -b20 | grep TASK | wc -l
68
crash> p sb_lock
sb_lock = $1 = {
{
rlock = {
raw_lock = {
lock = 1 '�01',
spinners = 49 '1'
}
}
}
}找内核栈上有哪些进程可能持有了sb_lock
search -t ffffffff823c4120 | grep TASK | awk '{print $4}' | sort > task_sb_list.txtcat foreach_bt.txt | grep shrink_slab -b20 | grep TASK | awk '{print $4}' | sort > task_shrink_slab.txt
cat foreach_bt.txt | grep shrink_slab -b20 | grep _raw_spin_lock -b20 | grep TASK | awk '{print $4}' | sort > task_spinlock.txt
cat foreach_bt.txt | grep prune_super -b20 | grep TASK | awk '{print $4}' | sort > task_prune_super.txt
sed 's/^/bt /g' task_sb_list.txt > comm.txt
[root@core-diag /data1/johnazhang/ieg_oom]# comm -23 task_prune_super.txt task_sb_list.txt
ffff880087e833a0
ffff88162121cd70
ffff881f89f6b3a0
ffff881f8d0233a0
ffff881f8d7833a0
ffff881f8d784d70
ffff881f8e6733a0
ffff881f8f7c4d70
ffff881f9315b3a0
ffff881f931a0000
ffff883f5a738000一一看遍,没有发现疑似持锁者,从代码里搜索了下,还有grab_super_passive可以持锁。
crash> foreach bt -a | grep super | grep -vE 'prune_super|put_super'
#5 [ffff881f93183830] grab_super_passive at ffffffff8118f93b
#5 [ffff881f89d77820] grab_super_passive at ffffffff8118f93b
#5 [ffff881f8f003830] grab_super_passive at ffffffff8118f93b
#5 [ffff883f5dadb830] grab_super_passive at ffffffff8118f93b
#5 [ffff881f8ba83830] grab_super_passive at ffffffff8118f93b
#5 [ffff883f5a5ff830] grab_super_passive at ffffffff8118f93b
#5 [ffff883f5efbf830] grab_super_passive at ffffffff8118f93b
#5 [ffff883f5d557830] grab_super_passive at ffffffff8118f93b
#5 [ffff881f8d83b830] grab_super_passive at ffffffff8118f93b
#5 [ffff883f513a3830] grab_super_passive at ffffffff8118f93b
#5 [ffff881f8978b830] grab_super_passive at ffffffff8118f93b
#5 [ffff881f8f697830] grab_super_passive at ffffffff8118f93b
#5 [ffff88063b127830] grab_super_passive at ffffffff8118f93b
#5 [ffff8800a5287830] grab_super_passive at ffffffff8118f93b
#5 [ffff880398457830] grab_super_passive at ffffffff8118f93b
#5 [ffff8803f1f7b830] grab_super_passive at ffffffff8118f93b
#5 [ffff88006ff3f830] grab_super_passive at ffffffff8118f93b
[root@core-diag /data1/johnazhang/ieg_oom]# comm -23 task_shrink_slab.txt task_spinlock.txt
ffff881f814919d0
ffff881f814933a0
ffff881f889a33a0
ffff881f89f199d0
ffff881f8eea0000
ffff881f8eea33a0
ffff8833df1acd70
ffff883c2d3719d0
ffff883f5da40000
ffff883f5e1d33a0
ffff883f5eec19d0可惜,再一一看遍,从这里面暂时无法确定sb_lock的owner。
因此分析到这里不禁怀疑是不是这个锁因为什么异常逻辑导致没被正常释放掉,从而死锁了?
尽管暂时没有抓到死锁的实锤,可以确认的是,shrink_slab里会有很多地方都在抢sb_lock锁。
同时,再上层shrinker也在去抢shrinker_rwsem。(上面分析过了两个锁的情况)
因此即使在正常的回收路径下,这样一大堆东西去抢锁,猴年马月才能进入oom路径?肯定慢!
trace数据分析
分析到这里,准备来实测一把,trace在direct_reclaim的耗时,到进入oom路径的时间。
由于direct_reclaim相关函数是inline的,没办法直接trace,同时为了测试控制变量,我们屏蔽掉cache的影响。因此其核心分配函数是get_page_from_freelist,其中回收内存的核心函数是shrink_zone(高版本为shrink_node)和shrink_slab,而shrink_zone主要是cgroup相关,我们这里测试不会用到,因此重点trace shrink_slab即可(从coredump里的堆栈是在shrink_slab也可以说明)。
trace逻辑解析
首先编写分配内存的测试程序mem.c:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
void func()
{
void *ptr;
unsigned long size = 1024*1024*1024;
ptr = malloc(size);
if(ptr == NULL)
{
size = 1024*1024;
ptr = malloc(size);
if(ptr == NULL)
{
printf("%d malloc failed
", getpid());
pthread_exit(0);
}
}
memset(ptr, 0, size);
while(1) {}
}
int main()
{
while(1)
{
pthread_t id;
int res;
res = pthread_create(&id, NULL, (void*) func, NULL);
if(res != 0)
{
printf("Create pthread error!
");
exit(1);
}
usleep(100000);
}
return 0;
}编写stap脚本shrink.stp来trace内核函数,并打印耗时分布:
global m, hist_shrink, time_begin, hist_oom, first_oom
probe begin
{
time_begin = gettimeofday_us()
first_oom = 0
}
probe kernel.function("shrink_slab")
{
m[pid()] = gettimeofday_us()
}
probe kernel.function("shrink_slab").return
{
hist_shrink <<< (gettimeofday_us() - m[pid()])
delete m[pid()]
}
probe kernel.function("out_of_memory")
{
delta = gettimeofday_us() - time_begin
hist_oom <<< delta
time_begin = gettimeofday_us()
if(!first_oom)
{
printf("@@@@@@ first oom takes %d us @@@@@@
", delta)
first_oom = 1
}
}
probe end
{
print("########## shrink_slab cost ###########
")
if(@count(hist_shrink))
{
print(@hist_log(hist_shrink))
}
print("
########## oom occurrence cost ########
")
if(@count(hist_oom))
{
print(@hist_log(hist_oom))
}
}这个脚本会打印三个东西,作用如下(统计时间均为us):
从运行脚本到第一次进入oom的时间,可以直观的看出进入oom的快慢shrink_slab函数的耗时分布直方图,可以直观的看出shrink_slab调用的耗时情况oom的间隔分布(两次触发oom的时差)直方图,可以直观的看出oom的频率高低(这里其实没怎么用到,因为前两者已经能很直观的说明问题了)开始测试,每组测试贴两组数据用于对比。
纯分配内存场景
【3.10】
test1:
@@@@@@ first oom takes 30661716 us @@@@@@

test2:
@@@@@@ first oom takes 31941301 us @@@@@@

【5.4】
test1:
@@@@@@ first oom takes 29123179 us @@@@@@

test2:
@@@@@@ first oom takes 30621499 us @@@@@@

【分析】
进入oom逻辑的耗时差异不大,5.4小胜一筹。
3.10的shrink_slab耗时分布大多集中在2-4us之间,而5.4则大多集中在1-2us之间,仍然小胜一筹。
注:超长耗时没有参考意义,和脚本结束的时间有关,这次测试数据中,5.4 oom了几次才手动停掉。
高流量(内网收包)+分配内存场景
从业务同学那里了解到,是大流量场景下,问题更容易复现,因此构造大流量场景。
测试方法: iperf -c 172.16.0.41 -t 240 -P 128 -i 1 向被测机器发包
【3.10】
test1:
@@@@@@ first oom takes 37717206 us @@@@@@


test2:
@@@@@@ first oom takes 38672782 us @@@@@@


【5.4】
test1:
@@@@@@ first oom takes 28713408 us @@@@@@


test2:
@@@@@@ first oom takes 27885962 us @@@@@@

【分析】
进入oom逻辑的耗时体现出了较大差异,5.4快了10秒左右。
3.10的shrink_slab耗时分布相较无流量时大幅增加,在2-4096us之间均匀分布,而5.4则仍然大多集中在1-2us之间,完胜3.10。
注:3.10这里出现了少量负统计,可能的原因一个是内核probe太多,被skip掉了出现统计偏差;一个是3.10对应的systemtap版本较老,相较下不够完善。不过误差数据仅是少量,不影响全局的统计分析。
高流量(内网同时收发包)+分配内存场景
同样的iperf,测试线程由128改为64,一台机器两个iperf一个作为s一个作为c,同时收发包。
【3.10】
test1:
@@@@@@ first oom takes 35546758 us @@@@@@

test2:
复现问题,机器hung死,没能统计到数据。


查看机器串口日志,看到了熟悉的堆栈:

对端机器打流接受不到:

这个case触发sysrq,分析见后面章节。
【5.4】
test1:
@@@@@@ first oom takes 30295935 us @@@@@@

test2:
@@@@@@ first oom takes 31409004 us @@@@@@

【分析】
3.10在不hung死的情况下,表现和前者类似,但是平均测试五次会出现一次hung死。
5.4的数据,和前两者相比无明显差异,完胜3.10。
vmcore 再分析
首先我们验证是不是卡死,当卡住问题出现时,查看串口记录时间15:50:

放着不管,一直卡了五个小时,怀疑是死锁的可能性很大:

开始分析hung死后sysrq生成的vmcore。
crash> ps -l | grep UN | tail
[83815905821155] [UN] PID: 31285 TASK: ffff881f7a920000 CPU: 49 COMMAND: "iperf"
[83815905817621] [UN] PID: 31223 TASK: ffff881f8a1399d0 CPU: 49 COMMAND: "iperf"
[83815905813612] [UN] PID: 31297 TASK: ffff8806a7160000 CPU: 49 COMMAND: "iperf"
[83815905813072] [UN] PID: 31327 TASK: ffff88101030b3a0 CPU: 49 COMMAND: "iperf"
[83815905812564] [UN] PID: 31276 TASK: ffff881f34764d70 CPU: 49 COMMAND: "iperf"
[83815905811787] [UN] PID: 31268 TASK: ffff881f84e98000 CPU: 49 COMMAND: "iperf"
[83815905804920] [UN] PID: 31316 TASK: ffff881f92d44d70 CPU: 49 COMMAND: "iperf"
[83815905757915] [UN] PID: 31204 TASK: ffff8808d21b99d0 CPU: 51 COMMAND: "iperf"
[83815905730859] [UN] PID: 31357 TASK: ffff881f842533a0 CPU: 38 COMMAND: "iperf"
[83815903342632] [UN] PID: 32292 TASK: ffff881f821533a0 CPU: 30 COMMAND: "mem"
crash> bt ffff881f821533a0
PID: 32292 TASK: ffff881f821533a0 CPU: 30 COMMAND: "mem"
#0 [ffff8814d439f830] __schedule at ffffffff819d023e
#1 [ffff8814d439f898] schedule at ffffffff819d0789
#2 [ffff8814d439f8a8] throttle_direct_reclaim at ffffffff81133e66
#3 [ffff8814d439f918] try_to_free_pages at ffffffff811383b4
#4 [ffff8814d439f9c0] __alloc_pages_nodemask at ffffffff8112d654
#5 [ffff8814d439faf8] alloc_pages_current at ffffffff81168d49
#6 [ffff8814d439fb40] new_slab at ffffffff8116f965
#7 [ffff8814d439fb78] __slab_alloc at ffffffff819c514a
#8 [ffff8814d439fc58] kmem_cache_alloc at ffffffff8117434b
#9 [ffff8814d439fc98] taskstats_exit at ffffffff810e7491
#10 [ffff8814d439fce8] do_exit at ffffffff81051240
#11 [ffff8814d439fd78] do_group_exit at ffffffff81051b9f
#12 [ffff8814d439fda8] get_signal_to_deliver at ffffffff810621b6
#13 [ffff8814d439fe40] do_signal at ffffffff81002437
#14 [ffff8814d439ff30] do_notify_resume at ffffffff81002af8
#15 [ffff8814d439ff50] retint_signal at ffffffff819d305f
RIP: 0000000000400828 RSP: 00007f6a8a7faf00 RFLAGS: 00000246
RAX: 00007f4fd3fff010 RBX: 0000000000000000 RCX: 00007f5013fff000
RDX: 00007f5013fff000 RSI: 0000000000000000 RDI: 00007f4fd3fff010
RBP: 00007f6a8a7faf10 R8: ffffffffffffffff R9: 0000000040000000
R10: 0000000000000022 R11: 0000000000001000 R12: 0000000000000000
R13: 0000000000801000 R14: 0000000000000000 R15: 00007f6a8a7fb700
ORIG_RAX: ffffffffffffffff CS: 0033 SS: 002b
crash> ps -l | grep UN | tail
[83815905821155] [UN] PID: 31285 TASK: ffff881f7a920000 CPU: 49 COMMAND: "iperf"
[83815905817621] [UN] PID: 31223 TASK: ffff881f8a1399d0 CPU: 49 COMMAND: "iperf"
[83815905813612] [UN] PID: 31297 TASK: ffff8806a7160000 CPU: 49 COMMAND: "iperf"
[83815905813072] [UN] PID: 31327 TASK: ffff88101030b3a0 CPU: 49 COMMAND: "iperf"
[83815905812564] [UN] PID: 31276 TASK: ffff881f34764d70 CPU: 49 COMMAND: "iperf"
[83815905811787] [UN] PID: 31268 TASK: ffff881f84e98000 CPU: 49 COMMAND: "iperf"
[83815905804920] [UN] PID: 31316 TASK: ffff881f92d44d70 CPU: 49 COMMAND: "iperf"
[83815905757915] [UN] PID: 31204 TASK: ffff8808d21b99d0 CPU: 51 COMMAND: "iperf"
[83815905730859] [UN] PID: 31357 TASK: ffff881f842533a0 CPU: 38 COMMAND: "iperf"
[83815903342632] [UN] PID: 32292 TASK: ffff881f821533a0 CPU: 30 COMMAND: "mem"
crash> bt ffff881f821533a0
PID: 32292 TASK: ffff881f821533a0 CPU: 30 COMMAND: "mem"
#0 [ffff8814d439f830] __schedule at ffffffff819d023e
#1 [ffff8814d439f898] schedule at ffffffff819d0789
#2 [ffff8814d439f8a8] throttle_direct_reclaim at ffffffff81133e66
#3 [ffff8814d439f918] try_to_free_pages at ffffffff811383b4
#4 [ffff8814d439f9c0] __alloc_pages_nodemask at ffffffff8112d654
#5 [ffff8814d439faf8] alloc_pages_current at ffffffff81168d49
#6 [ffff8814d439fb40] new_slab at ffffffff8116f965
#7 [ffff8814d439fb78] __slab_alloc at ffffffff819c514a
#8 [ffff8814d439fc58] kmem_cache_alloc at ffffffff8117434b
#9 [ffff8814d439fc98] taskstats_exit at ffffffff810e7491
#10 [ffff8814d439fce8] do_exit at ffffffff81051240
#11 [ffff8814d439fd78] do_group_exit at ffffffff81051b9f
#12 [ffff8814d439fda8] get_signal_to_deliver at ffffffff810621b6
#13 [ffff8814d439fe40] do_signal at ffffffff81002437
#14 [ffff8814d439ff30] do_notify_resume at ffffffff81002af8
#15 [ffff8814d439ff50] retint_signal at ffffffff819d305f
RIP: 0000000000400828 RSP: 00007f6a8a7faf00 RFLAGS: 00000246
RAX: 00007f4fd3fff010 RBX: 0000000000000000 RCX: 00007f5013fff000
RDX: 00007f5013fff000 RSI: 0000000000000000 RDI: 00007f4fd3fff010
RBP: 00007f6a8a7faf10 R8: ffffffffffffffff R9: 0000000040000000
R10: 0000000000000022 R11: 0000000000001000 R12: 0000000000000000
R13: 0000000000801000 R14: 0000000000000000 R15: 00007f6a8a7fb700
ORIG_RAX: ffffffffffffffff CS: 0033 SS: 002b
crash> task -R sched_info ffff881f821533a0
PID: 32292 TASK: ffff881f821533a0 CPU: 30 COMMAND: "mem"
sched_info = {
pcount = 2104490,
run_delay = 6188732079092,
last_arrival = 83815903342632,
last_queued = 0
}, 这里说明虽然是D进程,但并没有长时间hung死,是在正常RU的。
crash> log | grep sysrq
[83815.596853] IP: [<ffffffff813c5156>] sysrq_handle_crash+0x16/0x20
[83815.644437] RIP: 0010:[<ffffffff813c5156>] [<ffffffff813c5156>] sysrq_handle_crash+0x16/0x20
[83815.749252] [<ffffffff813c5912>] __handle_sysrq+0xa2/0x170
[83815.752243] [<ffffffff813c5d65>] sysrq_filter+0x335/0x420
[83815.904536] RIP [<ffffffff813c5156>] sysrq_handle_crash+0x16/0x20
crash> pd 83815-83815
$1 = 0这里找到对应代码位置,可以看出,这种在throttle的堆栈,都是在等kswapd去唤醒。

看看kswapd
crash> bt ffff881f8cc019d0
PID: 350 TASK: ffff881f8cc019d0 CPU: 2 COMMAND: "kswapd0"
#0 [ffff881fbfa45e70] crash_nmi_callback at ffffffff810294e2
#1 [ffff881fbfa45e80] nmi_handle at ffffffff819d3ee9
#2 [ffff881fbfa45ec8] do_nmi at ffffffff819d4000
#3 [ffff881fbfa45ef0] end_repeat_nmi at ffffffff819d3511
[exception RIP: _raw_spin_lock+29]
RIP: ffffffff819d2a6d RSP: ffff881f8f6bbc38 RFLAGS: 00000297
RAX: 0000000000000001 RBX: ffff883f5c9ed000 RCX: 0000000000000000
RDX: 0000000000000001 RSI: ffff881f8f6bbd88 RDI: ffffffff8238a120
RBP: ffff881f8f6bbc38 R8: 0000000000000000 R9: 0000000000000f85
R10: 000000000001f733 R11: 0000000000000000 R12: ffff883f5c9ed000
R13: 0000000000000000 R14: ffff881f8f6bbd88 R15: ffff883f5c9ed3b0
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
--- <NMI exception stack> ---
#4 [ffff881f8f6bbc38] _raw_spin_lock at ffffffff819d2a6d
#5 [ffff881f8f6bbc40] put_super at ffffffff8118e9b9
#6 [ffff881f8f6bbc58] prune_super at ffffffff8118fb7e
#7 [ffff881f8f6bbc90] shrink_slab at ffffffff81134de1
#8 [ffff881f8f6bbe20] kswapd at ffffffff81138f94
#9 [ffff881f8f6bbec8] kthread at ffffffff8107366f
#10 [ffff881f8f6bbf50] ret_from_fork at ffffffff81aab3c8 bt -z结果,省略无关信息:
#4 [ffff881f8f6bbc38] _raw_spin_lock (raw_spinlock_t * arg0= ffffffff8238a120) at ffffffff819d2a6d
crash> sym sb_lock
ffffffff8238a120 (B) sb_lock也是在抢sb_lock。
这里就知道,kswapd在prune_super的争抢sb_lock路上,且是有成功抢到过(不然无法唤醒上面那种在throttle的进程,而在throttle的进程没有长时间D住,说明是一直在被成功唤醒过)。
static void put_super(struct super_block *sb)
{
spin_lock(&sb_lock);
__put_super(sb);
spin_unlock(&sb_lock);
}
crash> foreach bt -a | grep __put_super
crash>
crash> sym __put_super
ffffffff8118e910 (t) __put_super 搜索代码,查看所有可能获取sb_lock的代码段:
crash> foreach bt -a | grep bdi_prune_sb
crash>
crash>
crash> foreach bt -a | grep do_emergency_remount
crash> foreach bt -a | grep generic_shutdown_super
crash>
crash> foreach bt -a | grep user_get_super
crash> foreach bt -a | grep get_super
crash> foreach bt -a | grep __releases确认只有put_super和grab_super_passive在尝试获取sb_lock。
查看grab_super_passive
bool grab_super_passive(struct super_block *sb)
{
spin_lock(&sb_lock);
if (hlist_unhashed(&sb->s_instances)) {
spin_unlock(&sb_lock);
return false;
}
sb->s_count++;
spin_unlock(&sb_lock);
if (down_read_trylock(&sb->s_umount)) {
if (sb->s_root && (sb->s_flags & MS_BORN))
return true;
up_read(&sb->s_umount);
}
put_super(sb);
return false;
}
foreach bt -a | grep grab_super_passive -b20 | grep TASK | awk '{print $4}' | sort > grab.txt
crash /boot/vmlinux /var/crash/2022-02-18-20:45/vmcore -i grab.txt 挨个遍历这些task在grab_super_passive上堆栈:
发现一个可疑的持锁者
crash> bt ffff883f624819d0
PID: 236 TASK: ffff883f624819d0 CPU: 45 COMMAND: "kworker/45:0"
#0 [ffff88403f3a5e70] crash_nmi_callback at ffffffff810294e2
#1 [ffff88403f3a5e80] nmi_handle at ffffffff819d3ee9
#2 [ffff88403f3a5ec8] do_nmi at ffffffff819d4000
#3 [ffff88403f3a5ef0] end_repeat_nmi at ffffffff819d3511
[exception RIP: down_read_trylock+26]
RIP: ffffffff8107819a RSP: ffff883f6248f7a8 RFLAGS: 00000246
RAX: 0000000000000000 RBX: ffff883f620e3000 RCX: 0000000000000000
RDX: 0000000000000001 RSI: ffff883f6248f940 RDI: ffff883f620e3068
RBP: ffff883f6248f7a8 R8: 0000000000000000 R9: 0000000000000040
R10: 0000000000000000 R11: 0000000000000003 R12: ffff883f620e3068
R13: ffff883f6248f940 R14: ffff883f6248f940 R15: ffff883f620e33b0
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
--- <NMI exception stack> ---
#4 [ffff883f6248f7a8] down_read_trylock at ffffffff8107819a
#5 [ffff883f6248f7b0] grab_super_passive at ffffffff8118f92f
#6 [ffff883f6248f7d0] prune_super at ffffffff8118fa67
#7 [ffff883f6248f808] shrink_slab at ffffffff81134de1
#8 [ffff883f6248f930] try_to_free_pages at ffffffff81138405
#9 [ffff883f6248f9d8] __alloc_pages_nodemask at ffffffff8112d654
#10 [ffff883f6248fb10] alloc_pages_current at ffffffff81168d49
#11 [ffff883f6248fb58] bio_copy_user_iov at ffffffff811c3d38
#12 [ffff883f6248fbd0] bio_copy_kern at ffffffff811c3f9e
#13 [ffff883f6248fc20] blk_rq_map_kern at ffffffff812f8494
#14 [ffff883f6248fc58] scsi_execute at ffffffff8148fcd8
#15 [ffff883f6248fca0] scsi_execute_req_flags at ffffffff8149142c
#16 [ffff883f6248fd08] sr_check_events at ffffffffa002e82b [sr_mod]
#17 [ffff883f6248fd78] cdrom_check_events at ffffffffa0010058 [cdrom]
#18 [ffff883f6248fd90] sr_block_check_events at ffffffffa002ecb9 [sr_mod]
#19 [ffff883f6248fdb0] disk_check_events at ffffffff812fcc4a
#20 [ffff883f6248fe10] disk_events_workfn at ffffffff812fcd86
#21 [ffff883f6248fe20] process_one_work at ffffffff8106beac
#22 [ffff883f6248fe68] worker_thread at ffffffff8106cd5b
#23 [ffff883f6248fec8] kthread at ffffffff8107366f
#24 [ffff883f6248ff50] ret_from_fork at ffffffff81aab3c8
crash> search -t ffffffff8238a120 | grep ffff883f624819d0
PID: 236 TASK: ffff883f624819d0 CPU: 45 COMMAND: "kworker/45:0"但是从代码逻辑上看,这个锁应该已经释放了才会走到这个堆栈上,但如果是这样,就没有其他的路径在等这个锁了,逻辑上似乎说不通。
但另一个可能是,另一个进程在在_raw_spin_lock中的正好执行到获取锁,但是还没走到__put_super,因此在堆栈里没有体现出来?
总之这个进程比较特殊,先继续往下分析看看能挖出什么信息:
crash> dis -r ffffffff8118f92f
0xffffffff8118f8f0 <grab_super_passive>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff8118f8f5 <grab_super_passive+5>: push %rbp
0xffffffff8118f8f6 <grab_super_passive+6>: mov %rsp,%rbp
0xffffffff8118f8f9 <grab_super_passive+9>: push %r12
0xffffffff8118f8fb <grab_super_passive+11>: push %rbx
0xffffffff8118f8fc <grab_super_passive+12>: mov %rdi,%rbx
0xffffffff8118f8ff <grab_super_passive+15>: mov $0xffffffff8238a120,%rdi
0xffffffff8118f906 <grab_super_passive+22>: callq 0xffffffff819d2a50 <_raw_spin_lock>
0xffffffff8118f90b <grab_super_passive+27>: cmpq $0x0,0x140(%rbx)
0xffffffff8118f913 <grab_super_passive+35>: je 0xffffffff8118f960 <grab_super_passive+112>
0xffffffff8118f915 <grab_super_passive+37>: addl $0x1,0x88(%rbx)
0xffffffff8118f91c <grab_super_passive+44>: movb $0x0,0x11fa7fd(%rip) # 0xffffffff8238a120 <sb_lock>
0xffffffff8118f923 <grab_super_passive+51>: lea 0x68(%rbx),%r12
0xffffffff8118f927 <grab_super_passive+55>: mov %r12,%rdi
0xffffffff8118f92a <grab_super_passive+58>: callq 0xffffffff81078180 <down_read_trylock>
0xffffffff8118f92f <grab_super_passive+63>: test %eax,%eax
crash> whatis grab_super_passive
bool grab_super_passive(struct super_block *);
bt -z
#5 [ffff883f6248f7b0] grab_super_passive (struct super_block * arg0= ffff883f620e3000) at ffffffff8118f92f
crash> mount | grep ffff883f620e3000
ffff883f620ca900 ffff883f620e3000 tmpfs tmpfs /sys/fs/cgroup
crash> super_block -xo | grep 0x68
[0x68] struct rw_semaphore s_umount;
crash> super_block.s_umount ffff883f620e3000
s_umount = {
count = 1,
wait_lock = {
raw_lock = {
lock = 0 '�00',
spinners = 0 '�00'
}
},
wait_list = {
next = 0xffff883f620e3078,
prev = 0xffff883f620e3078
}
}
crash> search -t ffff883f620e3000
PID: 236 TASK: ffff883f624819d0 CPU: 45 COMMAND: "kworker/45:0"
ffff883f6248f7c0: ffff883f620e3000没有人在跟他抢这个rwsem,也就是说是正好执行到这里的。
crash> super_block.s_root,s_flags ffff883f620e3000
s_root = 0xffff883f6298e0c8
s_flags = 1879113729
#define MS_BORN (1<<29)
crash> eval -b 1879113729
hexadecimal: 70010001
decimal: 1879113729
octal: 16000200001
binary: 0000000000000000000000000000000001110000000000010000000000000001
bits set: 30 29 28 16 0 也就是说grab_super_passive会return true。

这样他会走到下面的drop_super锁里,继续去尝试获取sb_lock,换句话说,这个进程证明了sb_lock是可以被获取的,这种情况不能算是死锁,更类似是“活锁”?
另外这个进程说明了,prune_super不会返回-1,这个信息很关键。
这样再往外跳一层看shrink_slab

有没有可能是这个死循环出不去了?
要看看,total_scan和batch_size分别是什么。
crash> dis -rl shrink_slab
省略无用信息。
0xffffffff81134e5c <shrink_slab+300>: cmp %r12,%rbx
0xffffffff81134e5f <shrink_slab+303>: jg 0xffffffff81134f26 <shrink_slab+502>
0xffffffff81134e65 <shrink_slab+309>: mov %r12,-0x30(%rbp)
0xffffffff81134e69 <shrink_slab+313>: nopl 0x0(%rax)
。。。。。。。。。。
0xffffffff81134eb3 <shrink_slab+387>: sub %rbx,-0x30(%rbp)
rbx==batch_size
r12==rbp-0x30==total_scan
crash> bt ffff881f56450000 -f
省略无关信息。
#7 [ffff881f8d07b888] shrink_slab at ffffffff81134de1
ffff881f8d07b890: ffff88203ffdab48 ffff881f8d07b9a8
ffff881f8d07b8a0: 0000000000000000 ffffffff82022f60
ffff881f8d07b8b0: 0000000000000000 00000000000000ac
ffff881f8d07b8c0: 0000000000000080 0000000000000000
ffff881f8d07b8d0: 00000000000000ab 0000000000000020
ffff881f8d07b8e0: 0000000000000000 0000000000000000
ffff881f8d07b8f0: 0000000000000000 0000000000000000
ffff881f8d07b900: ffff88203ffdab48 00000000000000ab
ffff881f8d07b910: 0000000001320122 ffff881f8d07b9d0
ffff881f8d07b920: ffff881f8d07b9a8 ffffffff819d4fd9
ffff881f8d07b930: 0000000000000202 ffff881f8d07b9c0
ffff881f8d07b940: ffff881f8d07bb50 ffff881f564508a0
ffff881f8d07b950: 00ff881f8d07b990 ffff88203ffdab08
ffff881f8d07b960: 0000000000000000 0000000000000000
ffff881f8d07b970: 0000000000000000 00000000b271c498
ffff881f8d07b980: 0000000000000040 ffff881f8d07b9d0
ffff881f8d07b990: 0000000000000000 ffff88203ffdab00
ffff881f8d07b9a0: 00000000000201da ffff881f8d07ba50
ffff881f8d07b9b0: ffffffff81138405
batch_size = 00000000b271c498
crash> eval 00000000b271c498
hexadecimal: b271c498
decimal: 2993800344
octal: 26234342230
binary: 0000000000000000000000000000000010110010011100011100010010011000这个值太大了,走读了代码,这显然不可能。

来确认下相关的值:
crash> shrink_control ffff881f8d07b9c0
struct shrink_control {
gfp_mask = 131546,
nr_to_scan = 0
}
crash> shrinker ffff883f5c9ea3b0
struct shrinker {
shrink = 0xffffffff8118fa30 <prune_super>,
seeks = 2,
batch = 1024,
list = {
next = 0xffff883f5c9e9bc8,
prev = 0xffff883f5c9eabc8
},
nr_in_batch = {
counter = 0
}
}
if (nr_pages_scanned == 0)
nr_pages_scanned = SWAP_CLUSTER_MAX;
#define SWAP_CLUSTER_MAX 32UL 确实对不上,那么问题出在哪里?
再回头来看看堆栈:
#6 [ffff881f8d07b850] prune_super at ffffffff8118fb7e
ffff881f8d07b858: 0000000000000400 ffff88203ffdab48
ffff881f8d07b868: ffff881f8d07b9c0 0000000000000000
ffff881f8d07b878: ffff883f5c9ea3b0 ffff881f8d07b920
ffff881f8d07b888: ffffffff81134de1
#7 [ffff881f8d07b888] shrink_slab at ffffffff81134de1
ffff881f8d07b890: ffff88203ffdab48 ffff881f8d07b9a8
ffff881f8d07b8a0: 0000000000000000 ffffffff82022f60
ffff881f8d07b8b0: 0000000000000000 00000000000000ac
ffff881f8d07b8c0: 0000000000000080 0000000000000000
ffff881f8d07b8d0: 00000000000000ab 0000000000000020
ffff881f8d07b8e0: 0000000000000000 0000000000000000
ffff881f8d07b8f0: 0000000000000000 0000000000000000
ffff881f8d07b900: ffff88203ffdab48 00000000000000ab
ffff881f8d07b910: 0000000001320122 ffff881f8d07b9d0
ffff881f8d07b920: ffff881f8d07b9a8 ffffffff819d4fd9
ffff881f8d07b930: 0000000000000202 ffff881f8d07b9c0
ffff881f8d07b940: ffff881f8d07bb50 ffff881f564508a0
ffff881f8d07b950: 00ff881f8d07b990 ffff88203ffdab08
ffff881f8d07b960: 0000000000000000 0000000000000000
ffff881f8d07b970: 0000000000000000 00000000b271c498
ffff881f8d07b980: 0000000000000040 ffff881f8d07b9d0
ffff881f8d07b990: 0000000000000000 ffff88203ffdab00
ffff881f8d07b9a0: 00000000000201da ffff881f8d07ba50
ffff881f8d07b9b0: ffffffff81138405看到prune_super的栈帧是ffff881f8d07b920,但是bt -f记录的shrink_slab的栈帧是ffff881f8d07b9a8才对?
看下ffff881f8d07b928上的地址:
crash> sym ffffffff819d4fd9
ffffffff819d4fd9 (T) kretprobe_trampoline
kprobes!恍然大悟,我不是插入了内核probe来hook shrink_slab吗!这样就合理了,回过头来再看。
rbp-30 ffff881f8d07b8f0,值是0,也就是说,并没有在这个循环里进入死循环!!
那么再往回推,遍历链表的第一个shrinker这里能否直接continue?

这回需要确认max_pass,也就是要回过去确认prune_super的返回值
if (!grab_super_passive(sb))
return -1;
if (sb->s_op && sb->s_op->nr_cached_objects)
fs_objects = sb->s_op->nr_cached_objects(sb);
total_objects = sb->s_nr_dentry_unused +
sb->s_nr_inodes_unused + fs_objects + 1;
if (!total_objects)
total_objects = 1;
if (sc->nr_to_scan) { #前面已经知道该值为0,所以不会进入这个if
int dentries;
int inodes;
/* proportion the scan between the caches */
dentries = (sc->nr_to_scan * sb->s_nr_dentry_unused) /
total_objects;
inodes = (sc->nr_to_scan * sb->s_nr_inodes_unused) /
total_objects;
if (fs_objects)
fs_objects = (sc->nr_to_scan * fs_objects) /
total_objects;
/*
* prune the dcache first as the icache is pinned by it, then
* prune the icache, followed by the filesystem specific caches
*/
prune_dcache_sb(sb, dentries);
prune_icache_sb(sb, inodes);
if (fs_objects && sb->s_op->free_cached_objects) {
sb->s_op->free_cached_objects(sb, fs_objects);
fs_objects = sb->s_op->nr_cached_objects(sb);
}
total_objects = sb->s_nr_dentry_unused +
sb->s_nr_inodes_unused + fs_objects;
}
total_objects = (total_objects / 100) * sysctl_vfs_cache_pressure;
drop_super(sb);
return total_objects;
}
crash> p sysctl_vfs_cache_pressure
sysctl_vfs_cache_pressure = $3 = 100
crash> super_block.s_nr_dentry_unused,s_nr_inodes_unused,s_op ffff883f5c9ea000
s_nr_dentry_unused = 0
s_nr_inodes_unused = 0
s_op = 0xffffffff81ac8b40 <cgroup_ops>
crash> super_operations.nr_cached_objects 0xffffffff81ac8b40
nr_cached_objects = 0x0所以这里返回值是0,也就是说shrinker会被遍历下去。
如果这个推测是对的,那么不同的进程应该都在不同的shrinker上,随便验证几个:
bt -z 省略无用信息。
#6 [ffff883f5e357850] prune_super (struct shrinker * arg0= ffff883f5c9e83b0, struct shrink_control * arg1= ffff883f5e3579c0) at ffffffff8118fa67
#6 [ffff881f8f6bbc58] prune_super (struct shrinker * arg0= ffff883f5c9ed3b0, struct shrink_control * arg1= ffff881f8f6bbd88) at ffffffff8118fb7e
#6 [ffff881f8ea43850] prune_super (struct shrinker * arg0= ffff883f5c9ea3b0, struct shrink_control * arg1= ffff881f8ea439c0) at ffffffff8118fb7e确实都是不同的,因此也证明这里不是个死循环。
那么问题有可能出在shrink_slab的上一层吗?
来统计下堆栈分布:
crash> foreach bt -a | grep shrink_slab | wc -l
166
crash> foreach bt -a | grep try_to_free_pages | wc -l
315
crash> foreach bt -a | grep throttle_direct_reclaim | wc -l
151
crash> pd 166+151
$4 = 317throttle_direct_reclaim的堆栈进程是D进程,在开头分析过,在等kswapd在shrink_slab的堆栈获取到sb_lock后唤醒,没有长时间D住的,属于受害方。
再来确认下,是否所有shrink_slab的堆栈,都在调用246行的do_shrinker_shrink(对应代码里遍历链表的第一个shrinker)?因此要统计所有shrink_slab的入口。
foreach bt -a | grep shrink_slab | awk '{print $5}' | sed 's/^/dis -rl /g' | sed 's/$/|tail -2|head -1/g' > dis_comm.txt 执行结果发现,确实不是都在246那个循环里,截取部分结果:
mm/vmscan.c: 246
mm/vmscan.c: 329
mm/vmscan.c: 329
mm/vmscan.c: 246
mm/vmscan.c: 246
mm/vmscan.c: 329
mm/vmscan.c: 246
mm/vmscan.c: 246329是退出shrink_slab了,找出对应进程的堆栈看看。
74202-PID: 32101 TASK: ffff881f347ccd70 CPU: 11 COMMAND: "stapio"
774265- #0 [ffff881f4411b7f8] __schedule at ffffffff819d023e
774320- #1 [ffff881f4411b860] __cond_resched at ffffffff810825e6
774379- #2 [ffff881f4411b878] _cond_resched at ffffffff819d0b3a
774437: #3 [ffff881f4411b888] shrink_slab at ffffffff81134f09
774493- #4 [ffff881f4411b9b0] try_to_free_pages at ffffffff81138405
774555- #5 [ffff881f4411ba58] __alloc_pages_nodemask at ffffffff8112d654
774622- #6 [ffff881f4411bb90] alloc_pages_current at ffffffff81168d49
774686- #7 [ffff881f4411bbd8] __page_cache_alloc at ffffffff81123c27
774749- #8 [ffff881f4411bc10] filemap_fault at ffffffff81125e75
774807- #9 [ffff881f4411bc70] ext4_filemap_fault at ffffffff8123f4c6
774870-#10 [ffff881f4411bc98] __do_fault at ffffffff81149dee
774925-#11 [ffff881f4411bd28] handle_pte_fault at ffffffff8114d268
774986-#12 [ffff881f4411bdb0] handle_mm_fault at ffffffff8114e77f
775046-#13 [ffff881f4411be28] __do_page_fault at ffffffff819d68d1
775106-#14 [ffff881f4411bf30] do_page_fault at ffffffff819d6c9e
775164-#15 [ffff881f4411bf40] do_async_page_fault at ffffffff819d6388
775228-#16 [ffff881f4411bf50] async_page_fault at ffffffff819d31c8
775289- RIP: 00007f7c969dd720 RSP: 00007ffdd8c494e8 RFLAGS: 00010202
775356- RAX: 0000000000000001 RBX: 000000001dcd6500 RCX: 0000000000000000
775428- RDX: 0000000000000000 RSI: 00007ffdd8c49600 RDI: 0000000000000005
775500- RBP: 0000000000008002 R8: 00007ffdd8c49520 R9: 00007ffdd8c49700
775572- R10: 0000000000000000 R11: 0000000000000293 R12: ffffffffffffffff
775644- R13: 00007f7c97d70088 R14: 00007f7c97d70098 R15: 00007f7c97d57008
775716- ORIG_RAX: ffffffffffffffff CS: 0033 SS: 002b
--
776684- R13: ffff883f52f6ff78 R14: 00007f7c97d57008 R15: 00007f7c97d70088
776756- ORIG_RAX: 0000000000000080 CS: 0033 SS: 002b就是执行完了调度走,更加说明了并不是一直在shrink_slab里跑。
陷入僵局,继续一一排查throttle_direct_reclaim和try_to_free_pages
foreach bt -a | grep throttle_direct_reclaim | awk '{print $5}' | sed 's/^/dis -rl /g' | sed 's/$/|tail -3|head -1/g' > throttle_comm.txtthrottle全部是/vmscan.c: 2394
也就是确认之前对throttle这个堆栈的理解是对的。
foreach bt -a | grep shrink_slab -C1 | grep try_to_free_pages | awk '{print $5}' | sed 's/^/dis -rl /g' | sed 's/$/|tail -6|head -1/g' > try_to_free_pages_comm.txttry_to_free_pages全部是mm/vmscan.c: 2436
也就是说try_to_free_pages进入shrink_slab的入口也是唯一的。
再往上层
crash> foreach bt -a | grep __alloc_pages_nodemask | wc -l
316这里比try_to_free_pages多出来的,也是在direct_reclaim上:
0xffffffff8112d60c <__alloc_pages_nodemask+1660>: callq 0xffffffff819d0b00 <_cond_resched>
0xffffffff8112d611 <__alloc_pages_nodemask+1665>: cmpl $0x0,0xef5dfc(%rip) # 0xffffffff82023414 <cpuset_memory_pressure_enabled>
到这里,能确定不是shrink_slab出现死循环,疑似是direct_recliam出现了死循环(也就是direct_recliam机制本身不健全的几率较大),无法进入oom,暂无法确定是有死锁。
继续分析下去,仅靠vmcore难度较高,因此回归主题,从这个case观察到的现象来对比分析下5.4和3.10的代码,来解析下为何5.4的路径要快。
3.10-5.4内存回收路径代码举例对比分析
进入oom的条件
从前面的trace数据中第一次进入oom的时间数据可以体现,5.4优于3.10;从前面的vmcore分析也可以看出,3.10的direct_recliam机制大概率有问题。
看一下核心代码逻辑的对比。
【3.10】
进入oom的条件忽略GFP标志的硬性要求,只看did_some_progress的值来判断


之前也分析过,在我们的场景下,堆栈在throotle的等待完是会返回0


因此全看do_try_to_free_pages的返回值
【5.4】
不再单一以did_some_progress来判断,判断机制相较3.10更为健全

should_reclaim_retry代码较复杂,这里详细逻辑分析后续补充
direct_recliam的回收速度
这里从前面的trace数据shrink_slab的耗时分布可以看出,5.4优于3.10。
这里以前面分析过的slowpath->direct_recliam->shrinker->prune_super路径来举例说明。
【3.10】
shirnker基本均为各个文件系统的prune_super,其作用是回收文件系统元数据数据结构,路径为prune_super->grab_super_passive->put_super(返回后继续)->drop_super->put_super,grab_super_passive和put_super均需要抢全局锁sb_lock,效率极低。


可以看到,grab_super_passive还需要获取sb->s_umount信号量。

【5.4】
优化掉prune_super,使用super_cache_scan实现替代,同时也优化掉了sb_lock锁!

只trylock sb->s_umount信号量,重量轻了很多!

后话
5.4相较3.10内核在内存不足的场景下,更加稳定且性能更好已经可以从本文中的case分析得到一定程度上的证明,但本文中的场景也仅是抛砖引玉,3.10并非就这一个内存不足的场景有问题,总体相较5.4是差距明显。
其他场景比如,遇到堆栈卡在shrink_inactive_list堆栈上的例子,则很可能是patch:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=db73ee0d463799223244e96e7b7eea73b4a6ec31解决的问题,这里就不再针对其他case一一展开分析。
因此从云侧的角度,建议再遇到类似问题的同学可以逐步切到TencentOS Server (tkernel4, 基于5.4内核)来加强业务的稳定性。
加载全部内容