【Python实现网络爬虫】Scrapy爬取网易新闻(仅供学习交流使用!)
作者:快盘下载 人气:目录
1. 新建项目2. 修改itmes.py文件3. 定义spider,创建一个爬虫模板3.1 创建crawl爬虫模板3.2 补充知识:selectors选择器3.3. 分析网页内容主体标题时间分类4. 修改spider下创建的爬虫文件4.1 导入包最终代码1. 新建项目
在命令行窗口下输入scrapy startproject scrapytest, 如下
")
https://www.163.com/dy/article/G570TESI05372M9P.html?f=post2020_dy_recommends
主体
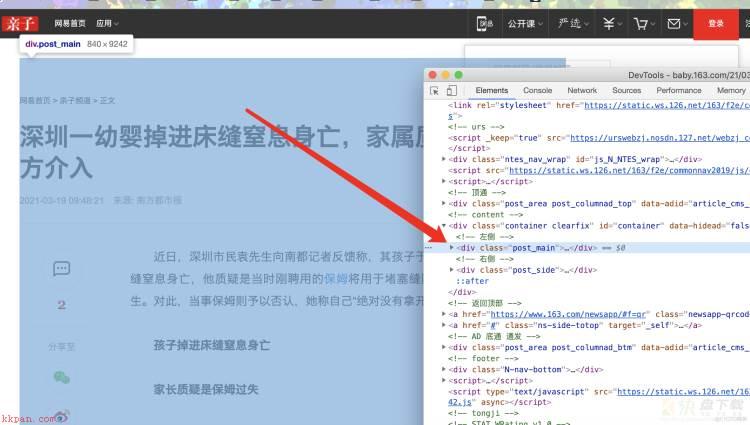
4. 修改spider下创建的爬虫文件4.1 导入包
打开创建的爬虫模板,进行代码的编写,除了导入系统自动创建的三个库,我们还需要导入news.items(这里就涉及到了包的概念了,最开始说的–init–.py文件存在说明这个文件夹就是一个包可以直接导入,不需要安装)
注意:使用的类ExampleSpider一定要继承自CrawlSpider,因为最开始我们创建的就是一个‘crawl’的爬虫模板,对应上
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*.163.com/d{2}/d{4}/d{2}/.*.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
return
Rule(LinkExtractor(allow=r’..163.com/d{2}/d{4}/d{2}/..html’), callback=‘parse’, follow=True), 其中第一个allow里面是书写正则表达式的(也是我们核心要输入的内容),第二个是回调函数,第三个表示是否允许深入
最终代码from datetime import datetime
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*.163.com/d{2}/d{4}/d{2}/.*.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'd{4}-d{2}-d{2} d{2}:d{2}:d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*.163.com/d{2}/d{4}/d{2}/.*.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'd{4}-d{2}-d{2} d{2}:d{2}:d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return
")
项目地址:https://gitee.com/codingce/codingce-scrapy
加载全部内容