Python处理Excel数据-pandas篇
作者:快盘下载 人气:在计算机编程中,pandas是Python编程语言的用于数据操纵和分析的软件库。特别是,它提供操纵数值表格和时间序列的数据结构和运算操作。它的名字衍生自术语“面板数据”(panel data),这是计量经济学的数据集术语,它们包括了对同一个体的在多个时期上的观测。它的名字是短语“Python data analysis”自身的文字游戏。
目录
Python处理Excel数据-pandas篇一、安装环境 1、打开以下文件夹(个人路径会有差异):2、按住左Shift右键点击空白处,选择【在此处打开Powershell窗口(s)】3、输入以下代码通过Pip进行安装Pandas库二、数据的新建、保存与整理 1、新建数据保存到Excel2、读取txt文件,将内容保存到Excel(引用B站UP 孙兴华示例文件)3、读取Excel及DataFrame的使用方式三、数据排序与查询 1、排序 例1:按语文分数排序降序,数学升序,英语降序例2:按索引进行排序2、查询 单条件查询多条件查询使用数据区间范围进行查询使用条件表达式进行查询一、安装环境
1、打开以下文件夹(个人路径会有差异):
C:UsersAdministratorAppDataLocalProgramsPythonPython38Scripts
Jetbrains全家桶1年46,售后保障稳定
2、按住左Shift右键点击空白处,选择【在此处打开Powershell窗口(s)】

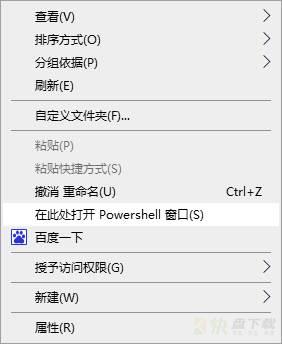
3、输入以下代码通过Pip进行安装Pandas库
./pip install pandas
./pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas

安装完成后会有提示:Successfully installed pandas

二、数据的新建、保存与整理
1、新建数据保存到Excel
import pandas as pd
path = 'E:python测试测试文件.xlsx'
data= pd.DataFrame({
'序号':[1,2,3],'姓名':['张三','李四','王五']})
data= data.set_index('序号') #设置索引列为'序号'列
data.to_excel(path) 2、读取txt文件,将内容保存到Excel(引用B站UP 孙兴华示例文件)
Txt文件:
E:python练习.txt
男,杨过,19,13901234567,终南山古墓,2000/1/1
女,小龙女,25,13801111111,终南山古墓,2000/1/2
男,郭靖,40,13705555555,湖北襄阳,2020/1/1
女,黄蓉,35,13601111111,湖北襄阳,2000/1/4
男,张无忌,18,13506666666,明教,2000/1/5
女,周芷若,17,13311111111,明教,2000/1/6
女,赵敏,17,18800000000,明教,2000/1/7
import pandas as pd path = r'E:python练习.txt' data = pd.read_csv(path,header=None,names=['性别','姓名','年龄','地址','号码','时间']) data.to_excel( r'E:python练习.xlsx') #将数据储存为Excel文件

3、读取Excel及DataFrame的使用方式
import pandas as pd
path = 'E:python测试数据查询.xlsx'
data = pd.DataFrame(pd.read_excel(path,sheet_name='Left',header=1,converters={
'A': str})) # converters={'A': str} 设置A列格式为文本
data.index # 查看索引
data.values # 查看数值
data.sort_index() # 按索引排序
data.sort_values() # 按数值排序
data.head( 5 ) # 查看前5行
data.tail( 3 ) # 查看后3行
data.values # 查看数值
datashape # 查看行数、列数
data.isnull() # 查找data中出现的空值
data.unique() # 查看唯一值
data.columns # 查看data的列名
data.sort_index() # 索引排序
data.sort_values() # 值排序
pd.merge(data1,data2) # 合并,以下为左连接
pd.merge(data1,data2,on=[a],how='left')
pd.concat([data1,data2]) # 合并,与merge的区别,自查**(特别注意要使用[])**
pd.Pivot_table( data ) # 用df做data透视表(类似于Excel的数透)
data.reset_index() # 修改、删除原有索引
data.reindex() # 重置索引,如下示例
data=data.reindex(columns=['商品名称', '规格', '对应车型类别', '备注', '新增的一列'], fill_value='新增的一列要填的值')
a=data['x'] # 取列名为'x'的列,格式为series
b=data[['x']] # 取列名为'x'的列,格式为Dataframe
c=data[['w','z']] # 取多列时需要用Dataframe的格式
data.loc['A'] # 取行名为'A'的行
data.loc[:,['x','z'] ] # 表示选取所有的行以及columns为x,z的列
data['name'].values # 取列名为'name'的列的值(取出来的是array而不是series)取单行后是一个Series,Series有index而无columns,可以用name来获取单列的索引
data.head(4) # 取头四行
data.tail(3) # 取尾三行
**data= data.iloc[2:, 2:20] # 选择2行开始、2-11列**
[m, n] = data.shape # 对m,n进行复制,m等于最大行数 n等于最大列数
data.notnull() # 非空值
data.dropna() # 删除空值
data.dropna() # 删除有空值的行
data.dropna(axis=1) # 删除有空值的列
data.dropna(how='all') # 删除所有值为Nan的行
data.dropna(thresh=2) # 至少保留两个非缺失值
data.strip() # 去除列表中的所有空格与换行符号
data.fillna(0) # 将空值填充0
data.replace(1, -1) # 将1替换成-1
data.fillna(100) # 填充缺失值为100
data.fillna({
'语文':100,'数学':100,}) # 不同列填充不同值
data.fillna(method='ffill') # 将空值填充为上一个值
data.fillna(method='bfill') # 将空值填充下一个值
data.fillna(method='bfill',limit=1) # 将空值填充下一个值,限制填充数量为1 三、数据排序与查询
1、排序
例1:按语文分数排序降序,数学升序,英语降序
import pandas as pd path = 'c:/pandas/排序.xlsx' data= pd.read_excel(path ,index_col='序号') data.sort_values(by=['语文','数学','英语'],inplace=True,ascending=[False,True,False]) print(data)
例2:按索引进行排序
import pandas as pd path = 'c:/pandas/排序.xlsx' data = pd.read_excel(路径,index_col='序号') data.sort_index(inplace=True) print(data)
2、查询
单条件查询
import pandas as pd path = 'c:/pandas/筛选.xlsx' data = pd.read_excel(path ,index_col='出生日期') print(data.loc['1983-10-27','语文'])
多条件查询
import pandas as pd path = 'c:/pandas/筛选.xlsx' data = pd.read_excel(path ,index_col='出生日期') print(data.loc['1983-10-27',['语文','数学','英语']])
使用数据区间范围进行查询
import pandas as pd path = 'c:/pandas/筛选.xlsx' data = pd.read_excel(path,index_col='出生日期') print(data.loc['1983-10-27':'1990-12-31',['语文','数学','英语']])
使用条件表达式进行查询
import pandas as pd path = 'c:/pandas/筛选.xlsx' data = pd.read_excel(路径,index_col='出生日期') print(data.loc[(data['语文'] > 60) & (data['英语'] < 60),:]) #这里的 ,: 指的是列取全部
今天的分享到此就结束啦,后续还会继续更新~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/222961.html原文链接:https://javaforall.cn
加载全部内容