python爬虫基础:Beautiful Soup用法详解
作者:快盘下载 人气:前言
说到爬虫,我们不得不提起beautiful soup这个爬虫利器,Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.它的官方文档是这样解释的,其实它已经说得非常清楚了,它就就是一个数据提取库
下面来看看,Beautiful Soup使用的演示过程吧
先看下所需网站的HTML标签

可以清楚地看见,文章得我标题都是在a标签当中的,这个可以用find_all('a', 'title') 提起数据了
具体代码如下:
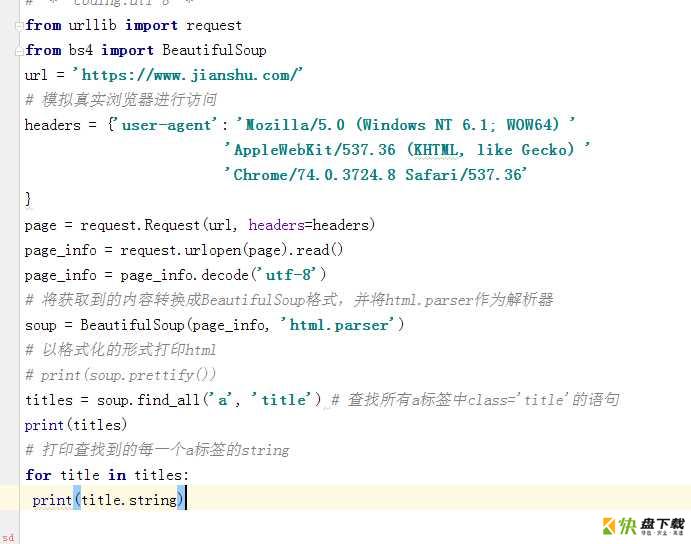
运行结果

还有更多的使用方法,可以去看看关于Beautiful Soup的文档详解
学习从来不是一个人的事情,要有个相互监督的伙伴,工作需要学习python或者有兴趣学习python的伙伴可以私信回复小编“学习” 获取资料,一起学习
加载全部内容